
在Binder系列文章中的第三篇,主要是讨论了addService的流程,一直讲到了talkWithDriver方法,在talkWithDriver中调用了ioctl(mProcess->mDriverFD, BINDER_WRITE_READ, &bwr)这个方法,之前也讲过了,这个方法调用内核的binder驱动,会陷入到内核binder驱动的binder_ioctl方法中,这篇文章就从这个方法开始讲起:
```c
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg) // 对设备进行操作的方法,比如注册初始化等等
{
int ret;
struct binder_proc *proc = filp->private_data; // 获取用户进程结构体
struct binder_thread *thread;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
/*printk(KERN_INFO "binder_ioctl: %d:%d %x %lx\n", proc->pid, current->pid, cmd, arg);*/
ret = wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2);
if (ret)
return ret;
mutex_lock(&binder_lock);
thread = binder_get_thread(proc); // 为这个进程创建一个线程结构体
if (thread == NULL) {
ret = -ENOMEM;
goto err;
}
switch (cmd) {
case BINDER_WRITE_READ: {
struct binder_write_read bwr;
if (size != sizeof(struct binder_write_read)) {
ret = -EINVAL;
goto err;
}
if (copy_from_user(&bwr, ubuf, sizeof(bwr))) { // 从用户空间复制bwr数据到这里,这里初始化service manager的时候,对应的是service manager中的binder_write中调用的ioctl
ret = -EFAULT;
goto err;
}
if (binder_debug_mask & BINDER_DEBUG_READ_WRITE)
printk(KERN_INFO "binder: %d:%d write %ld at %08lx, read %ld at %08lx\n",
proc->pid, thread->pid, bwr.write_size, bwr.write_buffer, bwr.read_size, bwr.read_buffer);
// 如果写入的数据大小大于0,则开始处理BINDER_WRITE_READ命令,即service manager中把自己主线程注册为binder线程
if (bwr.write_size > 0) {
ret = binder_thread_write(proc, thread, (void __user *)bwr.write_buffer, bwr.write_size, &bwr.write_consumed);
if (ret < 0) {
bwr.read_consumed = 0;
if (copy_to_user(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto err;
}
}
if (bwr.read_size > 0) { // 如果read缓冲区大小大于0,即用户向binder驱动请求数据
ret = binder_thread_read(proc, thread, (void __user *)bwr.read_buffer, bwr.read_size, &bwr.read_consumed, filp->f_flags & O_NONBLOCK);
if (!list_empty(&proc->todo))
wake_up_interruptible(&proc->wait);
if (ret < 0) {
if (copy_to_user(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto err;
}
}
if (binder_debug_mask & BINDER_DEBUG_READ_WRITE)
printk(KERN_INFO "binder: %d:%d wrote %ld of %ld, read return %ld of %ld\n",
proc->pid, thread->pid, bwr.write_consumed, bwr.write_size, bwr.read_consumed, bwr.read_size);
if (copy_to_user(ubuf, &bwr, sizeof(bwr))) {
ret = -EFAULT;
goto err;
}
break;
}
...................
default:
ret = -EINVAL;
goto err;
}
ret = 0;
err:
if (thread)
thread->looper &= ~BINDER_LOOPER_STATE_NEED_RETURN; // 修改该线程状态,已经初始化好了,后面能接受请求任务了。
mutex_unlock(&binder_lock);
wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2);
if (ret && ret != -ERESTARTSYS)
printk(KERN_INFO "binder: %d:%d ioctl %x %lx returned %d\n", proc->pid, current->pid, cmd, arg, ret);
return ret;
}
```
这个方法在binder第一篇文章讲service manager注册的时候也讲过,上面删除了一些和现在注册流程无关的代码,我们只聚焦在当前的流程上。前面调用talkWithDriver的时候,传入的cmd参数是BINDER_WRITE_READ是什么,我们看下他的定义:
```c
#define BINDER_WRITE_READ _IOWR('b', 1, struct binder_write_read)
#define _IOWR(type,nr,size) _IOC(_IOC_READ|_IOC_WRITE,(type),(nr),(_IOC_TYPECHECK(size)))
#define _IOC(dir,type,nr,size) \
(((dir) << _IOC_DIRSHIFT) | \
((type) << _IOC_TYPESHIFT) | \
((nr) << _IOC_NRSHIFT) | \
((size) << _IOC_SIZESHIFT))
........
```
他是一个宏定义,然后继续继续跟进去又是一连串的定义,最终就是做了一个位左移的运算,我们看到在BINDER_WRITE_READ在最后的参数是一个binder_write_read结构体,我们就只需要了解,这个命令的读写是和这个结构体有关的,他最后的运算的结果是把所有的参数做或运算,其中由于这个结构体长度最长,所以这个命令的长度不会超过这个结构体。
我们回到binder_ioctl方法,我们知道cmd是BINDER_WRITE_READ,所以case进入这个分支。先验证下这个命令的长度是否是等于binder_write_read这个结构体,然后调用copy_from_user(&bwr, ubuf, sizeof(bwr))把调用者那边的数据复制到内核中,这里bwr是在内核申请的binder_write_read结构体变量,ubuf是在调用者进程中的数据地址,由于不是一个进程,而调用者和内核也没进行过内存映射所以,需要调用copy_from_user方法把调用者进程中的数据复制到内核中才能进行操作,这个进程间数据的复制是比较耗时间,所以还记得吗前面在binder服务会和内核共享一片内存区域,大小是1M-8K,所以到后面我们可以看到binder驱动在和服务端交互的时候就不要像这里用copy_from_user或者copy_to_user进行读写了,到后面遇到的时候我们再说。这个内核把数据读到bwr变量中。
## 读取写缓冲区数据
接下去可以看到有两行这样的代码:
```c
if (bwr.write_size > 0)
............
if (bwr.read_size > 0)
```
可以看出该方法会读取写缓冲区和读缓冲区,如果有数据就会执行相应的方法。这里前面有在写缓冲区写入数据,所以接下去会执行binder_thread_write方法,我们看一下:
```c
// 进程给binder发送命令,比如用户空间的代理对象给binder引用对象。而read那个方法是用户态(client或server)项binder获取数据和命令
int binder_thread_write(struct binder_proc *proc, struct binder_thread *thread,
void __user *buffer, int size, signed long *consumed)
{
uint32_t cmd;
void __user *ptr = buffer + *consumed; // 用户缓冲区开始位置,这里是write方法,里面应该保存着上面传过来的参数
void __user *end = buffer + size; // 用户缓冲区结束位置
while (ptr < end && thread->return_error == BR_OK) {
if (get_user(cmd, (uint32_t __user *)ptr)) // 读取一个命令
return -EFAULT;
ptr += sizeof(uint32_t); // 指针前移
if (_IOC_NR(cmd) < ARRAY_SIZE(binder_stats.bc)) {
binder_stats.bc[_IOC_NR(cmd)]++;
proc->stats.bc[_IOC_NR(cmd)]++;
thread->stats.bc[_IOC_NR(cmd)]++;
}
switch (cmd) {
....................
case BC_TRANSACTION: // client给binder驱动发命令
case BC_REPLY: { // server段处理完了后,发给binder驱动,binder驱动再发给client说明已经梳理完了
struct binder_transaction_data tr;
// 从用户空间读取数据到tr,这里在内核开辟的只有binder_transaction_data结构体,不包括这里的缓冲区
// 缓冲区在binder_transaction里面会开辟,是开辟在目标server的进程空间
if (copy_from_user(&tr, ptr, sizeof(tr)))
return -EFAULT;
ptr += sizeof(tr); // 读取数据缓冲区指针前移
binder_transaction(proc, thread, &tr, cmd == BC_REPLY); // 处理命令
break;
}
...................
default:
printk(KERN_ERR "binder: %d:%d unknown command %d\n", proc->pid, thread->pid, cmd);
return -EINVAL;
}
*consumed = ptr - buffer;
}
return 0;
}
```
这个方法是非常的长,我们还是先截取目前流程相关的来看。开始的ptr指向读取缓冲区开始的位置,然后读取里面的数据。我们看到读取数据用的是get_user(cmd, (uint32_t __user *)ptr),这个命令表示从用户空间读取一个32位的数据,ptr只想的是一个binder_write_read结构体,之前我们用copy_from_user已经把这个结构体从用户空间复制到内核了,这里为什么又要从用户空间来复制呢,我们看下这个结构体的具体数据类型:
```c
struct binder_write_read {
signed long write_size; /* bytes to write */ // 缓冲区大小
signed long write_consumed; /* bytes consumed by driver */ // binder驱动已经处理了多少
unsigned long write_buffer; // 传给binder的缓冲区,在用户空间
signed long read_size; /* bytes to read */ // 缓冲区大小
signed long read_consumed; /* bytes consumed by driver */ // 已经读取了多少
unsigned long read_buffer; // binder返回给用户的数据缓冲区,在用户空间
};
```
这里我们读取的缓冲区是write_buffer这个字段,而这个字段的类型是long,即是一个地址,而这个地址是在用户空间的,我们虽然已经得到了这个结构体的数据,但是我们目前得到的仅仅是缓冲区的地址,而不是数据,他的数据还是用户空间,所以我们还是需要从用户空间来复制数据。另外简单说一下get_user只能从用户空间获取一些基本类型的数据,向结构体这种复杂数据还是需要用copy_from_user这种。
之前在用户空间往这个缓冲区写入的内容是什么,我们在回去看一眼:
```c++
binder_transaction_data tr;
..........
mOut.writeInt32(cmd); // 写入binder驱动需要的命令
mOut.write(&tr, sizeof(tr)); // 写入binder驱动需要的数据
```
我贴了一下最后写入的数据,可以看到先是一个命令,然后是一个binder_transaction_data结构体。所以现在读出的32位就是命令,即BC_TRANSACTION。我们继续看下面BC_TRANSACTION的分支.
## 封装写缓冲区命令
首先还是在内核中声明一个binder_transaction_data变量,然后调用copy_from_user(&tr, ptr, sizeof(tr))方法来复制这个结构体,最后调用binder_transaction(proc, thread, &tr, cmd == BC_REPLY)继续执行。这个都很简单,也不用多说,我们进入binder_transaction方法:
```c
// binder驱动处理用户发过来的命令和数据 reply = 0是发起命令 BC_TRANSACTION 1是回复命令 reply
static void binder_transaction(struct binder_proc *proc, struct binder_thread *thread,
struct binder_transaction_data *tr, int reply)
{
struct binder_transaction *t;
struct binder_work *tcomplete;
size_t *offp, *off_end;
struct binder_proc *target_proc;
struct binder_thread *target_thread = NULL;
struct binder_node *target_node = NULL; // 调用的实体对象
struct list_head *target_list;
wait_queue_head_t *target_wait;
struct binder_transaction *in_reply_to = NULL;
struct binder_transaction_log_entry *e;
uint32_t return_error;
e = binder_transaction_log_add(&binder_transaction_log);
e->call_type = reply ? 2 : !!(tr->flags & TF_ONE_WAY);
e->from_proc = proc->pid;
e->from_thread = thread->pid;
e->target_handle = tr->target.handle;
e->data_size = tr->data_size;
e->offsets_size = tr->offsets_size;
if (reply) { // reply==1,是BC_REPLY命令
.....
} else { // reply=0 发起命令 BC_TRANSACTION
if (tr->target.handle) { // 目标句柄,如果等于0就是service manager,走else分支,否则走这
struct binder_ref *ref;
ref = binder_get_ref(proc, tr->target.handle);
if (ref == NULL) {
binder_user_error("binder: %d:%d got "
"transaction to invalid handle\n",
proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
goto err_invalid_target_handle;
}
target_node = ref->node;
} else { // 句柄值为0,说明是service manager
target_node = binder_context_mgr_node; // 先获取service manager的实体对象
if (target_node == NULL) {
return_error = BR_DEAD_REPLY;
goto err_no_context_mgr_node;
}
}
e->to_node = target_node->debug_id;
target_proc = target_node->proc; // 获取实体对象的宿主进程,即service manager或者一个server
if (target_proc == NULL) {
return_error = BR_DEAD_REPLY;
goto err_dead_binder;
}
if (!(tr->flags & TF_ONE_WAY) && thread->transaction_stack) { // 如果是同步的通信,并且线程的事务堆栈中有数据
struct binder_transaction *tmp;
tmp = thread->transaction_stack; // 取出栈顶事务
if (tmp->to_thread != thread) { // 如果处理栈顶事务的线程不是本线程,报错
binder_user_error("binder: %d:%d got new "
"transaction with bad transaction stack"
", transaction %d has target %d:%d\n",
proc->pid, thread->pid, tmp->debug_id,
tmp->to_proc ? tmp->to_proc->pid : 0,
tmp->to_thread ?
tmp->to_thread->pid : 0);
return_error = BR_FAILED_REPLY;
goto err_bad_call_stack;
}
while (tmp) {
// 遍历栈事务,寻找栈中之前有没有同样的目标进程需要处理的事务的线程,有的话取出,用这个线程来现在的工作项,即把事务挂在那个线程后面。
// 这样做的话就不用占用其他线程,因为就算占用的了也需要等待这个线程处理完才可以处理当前事务,所以就放在一起,即这种情况是串行的
if (tmp->from && tmp->from->proc == target_proc) // 如果发起事务的线程存在,并且发起事务的线程的进程就是目标进程
target_thread = tmp->from; // 那么就取出这个发起事务的线程
tmp = tmp->from_parent; // 父事务
}
}
}
// 这里的target_thread是client或者server都可以,看是client向binder发请求,还是server向binder发请求
if (target_thread) { // 找到一个线程来处理事务
e->to_thread = target_thread->pid;
target_list = &target_thread->todo; // 获取线程的todo队列
target_wait = &target_thread->wait; // 获取线程的等待队列
} else { // 没找到线程的话。这里的target_proc应该是server进程
target_list = &target_proc->todo; // 获取进程的todo队列
target_wait = &target_proc->wait; // 获取线程的等待队列
}
e->to_proc = target_proc->pid;
.....................
}
```
这里又是一个非常长的方法,我们把代码分几段来分析,先贴出上面这段。开始是初始化一些和log相关的变量,之后我们看这个方法最后一个参数,由于之前是cmd == BC_REPLY这个值传入的,而当前我们的命令是BC_TRANSACTION,所以是false,跳到下面else去执行。
当前我们请求的是service manager,他的句柄值是0,所以还是走else。之前我们分析servic manager启动的时候,有分析过,service manager把他在内核中的实体对象保存在binder_node这个结构体上,即变量binder_node。我们把他保存在变量target_node上,然后target_proc = target_node->proc这句是把service manager的进程号保存在target_proc上。
找到了目标后,接下去我们要创建有一个事务来处理这个任务。事务也是一个结构体,用来描绘这项事务的一些信息:
```c
struct binder_transaction { // 描述一个binder事务
int debug_id;
struct binder_work work; // 工作类型
struct binder_thread *from; // 发起事务的线程
struct binder_transaction *from_parent; // 当前事务的前一个事务?
struct binder_proc *to_proc; // 处理这个事务的进程
struct binder_thread *to_thread; // 处理这个事务的线程
struct binder_transaction *to_parent; // 当前线程事务栈顶的前一个事务,也可以理解成当前栈顶的下一个事务
unsigned need_reply : 1; // 1表示同步事务,0表示异步事务。或者直接理解为1是需要回复该事务创建者,0不需要回复创建者
/*unsigned is_dead : 1;*/ /* not used at the moment */
struct binder_buffer *buffer; // 指向这个事务工作进程的缓冲区,保存了进程间通信数据,这个缓冲区是在内核中的,应该和server要映射,所以进程可以操作得到内核这里的缓冲区
unsigned int code;
unsigned int flags;
long priority; // 源线程的优先级
long saved_priority; // 在修改线程优先级时,会先把原来的优先级保存在这里,然后取源线程和目标service中大的一个
uid_t sender_euid; // 用户ID
};
```
我们知道每个进程有自己的binder线程来处理具体得binder事务,所以事务的结构体中会记录处理这项事务的线程。而每个线程可以处理多个事务,所以每个线程又有个自己的事务栈保存着这个线程正在处理的所有事务,这个栈的栈顶事务保存在这个线程的结构体中,所以每个线程也被定义为一个结构体:
```c
struct binder_thread { // 描述binder线程池中的线程
struct binder_proc *proc; // 宿主进程是server或者client?
struct rb_node rb_node; // 应该是binder_proc中threads中的一个节点
int pid;
int looper; // 描述当前线程的状态的,比如是否是binder线程,是否退出了,是否异常,是否空闲,是否初始化等等
struct binder_transaction *transaction_stack; // 线程处理的事务会被放在这个事务堆栈中
struct list_head todo; // 待处理事务
uint32_t return_error; /* Write failed, return error code in read buf */
uint32_t return_error2; /* Write failed, return error code in read */
/* buffer. Used when sending a reply to a dead process that */
/* we are also waiting on */
wait_queue_head_t wait; // 睡眠等待队列
struct binder_stats stats;
};
```
现在我们既然要创建一个事务,那么必须要给他一个处理这个事务的线程,比如我们这里这个事务是给service manager来处理的,那么我们就让这个事务的处理线程service manager,但是可能service manager有多个线程,我们应该把这个事务交给哪个线程最好呢,或者说有没有交给某个线程来说相对并发性更好一些呢?这里做了一点优化处理。比如说service manager有两个线程A和B,A是空闲的,B在处理一个事务,但是由于他需要我们现在这个进程先处理另一个事务才能继续处理,所以线程B被阻塞了。那么现在我们的这个进程在处理的时候又请求service manager来处理一个新事务,才能继续,那么是交给线程A还是线程B好呢?如果交给线程A当然可以,因为线程A本来就空闲的,所以这样等于A和B线程都有一个事务了,但是仔细一想是不是交给B更好呢,因为B本来就阻塞了,把事务交给他反正可以节省一个线程,那不是更好吗。所以这里while循环代码,如下:
```c
while (tmp) {
if (tmp->from && tmp->from->proc == target_proc)
target_thread = tmp->from;
tmp = tmp->from_parent;
}
```
就是寻找有没有这么个情况的线程,如果有就把事务交给他。如果找到了这样一个线程,我们就把这个线程的todo队列和wait队列取出,后面会往todo队列插入事务,然后唤醒wait队列。如果没有找到这样的线程,就会用进程的队列来处理。
我们继续看下下面一段代码:
```c
struct binder_transaction *t;
struct binder_work *tcomplete;
// 用来创建一个binder_transaction,用来给server工作,如果是server返回的时候,就是给client工作的
t = kzalloc(sizeof(*t), GFP_KERNEL);
if (t == NULL) {
return_error = BR_FAILED_REPLY;
goto err_alloc_t_failed;
}
binder_stats.obj_created[BINDER_STAT_TRANSACTION]++;
// 创建一个工作项,用来返回给发起client, 发回给client命令BINDER_WORK_TRANSACTION,用来通知client已经收到命令了
// 同理,如果是server返回的时候,就会发给server的
tcomplete = kzalloc(sizeof(*tcomplete), GFP_KERNEL);
if (tcomplete == NULL) {
return_error = BR_FAILED_REPLY;
goto err_alloc_tcomplete_failed;
}
binder_stats.obj_created[BINDER_STAT_TRANSACTION_COMPLETE]++;
t->debug_id = ++binder_last_id;
e->debug_id = t->debug_id;
.....................
if (!reply && !(tr->flags & TF_ONE_WAY)) // 如果是一个发起命令 BC_TRANSACTION reply==0 并且是同步通信
t->from = thread; // 把这个事务的发起线程指向现在这个
else // 到这里是一个回复给client的命令,不需要知道发起线程了
t->from = NULL;
t->sender_euid = proc->tsk->cred->euid;
t->to_proc = target_proc; // 处理这个事务的进程
t->to_thread = target_thread; // 处理这个事务的线程
t->code = tr->code; // 命令
t->flags = tr->flags; // 同步异步之类的
t->priority = task_nice(current); // 优先级
// 给处理这个事务的进程分配缓冲区,内核和进程共享
t->buffer = binder_alloc_buf(target_proc, tr->data_size,
tr->offsets_size, !reply && (t->flags & TF_ONE_WAY));
if (t->buffer == NULL) {
return_error = BR_FAILED_REPLY;
goto err_binder_alloc_buf_failed;
}
t->buffer->allow_user_free = 0; // 该缓冲区不空闲了
t->buffer->debug_id = t->debug_id;
t->buffer->transaction = t; // 这个缓冲区使用的事务
t->buffer->target_node = target_node; // 这个缓冲区使用的实体对象。 如果是server回复client的,这个为null
if (target_node) // 因为这个实体对象上面一句被引用了,所以需要增加一个强引用,后面binder_transaction_release会再减去引用计数
binder_inc_node(target_node, 1, 0, NULL);
```
这里创建了一个事务项t和工作项tcomplete,事务项就是前面介绍的描述这个事务相关的线程,进程等,而工作项是用来描述一个事务项的,里面有这个事务项的类型,后面我们会说到。我们先来看这个事务项的初始化,除了前面说到的处理该事务的进程,线程等等信息外,其中比较重要的是binder_alloc_buf这个方法,他是用来开辟一片内存空间,这片内存空间就是内核和服务端共享的区域,我们看下方法:
```c
// BC_TRANSACTION或者BC_REPLY向其他进程传数据的时候会调用
static struct binder_buffer *binder_alloc_buf(struct binder_proc *proc,
size_t data_size, size_t offsets_size, int is_async) // 分配缓冲区给目标进程proc,数据大小是data_size,偏移数组大小是offsets_size,is_async表示是否异步
{
struct rb_node *n = proc->free_buffers.rb_node;
struct binder_buffer *buffer;
size_t buffer_size;
struct rb_node *best_fit = NULL;
void *has_page_addr;
void *end_page_addr;
size_t size;
if (proc->vma == NULL) {
printk(KERN_ERR "binder: %d: binder_alloc_buf, no vma\n",
proc->pid);
return NULL;
}
// 总共需要分配的数据大小是多少
size = ALIGN(data_size, sizeof(void *)) +
ALIGN(offsets_size, sizeof(void *)); // 指针大小对齐获得数据和偏移数组(数据分为普通数据和binder对象,他们是混合在一起的,偏移数组保存的是binder对象在数据中的偏移位置)
if (size < data_size || size < offsets_size) { // 总大小于2个的值,说明溢出了,就会变小
binder_user_error("binder: %d: got transaction with invalid "
"size %zd-%zd\n", proc->pid, data_size, offsets_size);
return NULL;
}
if (is_async &&
proc->free_async_space < size + sizeof(struct binder_buffer)) { // 异步的话,检查一下是否大于异步的内存分配空间,是的话报错。注意数据是有数据头的,所以要加上binder_buffer大小
if (binder_debug_mask & BINDER_DEBUG_BUFFER_ALLOC)
printk(KERN_ERR "binder: %d: binder_alloc_buf size %zd f"
"ailed, no async space left\n", proc->pid, size);
return NULL;
}
while (n) { // 遍历内核空闲缓冲区红黑树节点
buffer = rb_entry(n, struct binder_buffer, rb_node); // 获取红黑树上的一个缓冲区结点
BUG_ON(!buffer->free);
buffer_size = binder_buffer_size(proc, buffer); // 获取这个缓冲区的大小
if (size < buffer_size) { // 找个一个缓冲区大小是大于目前需要大小的结点
best_fit = n; // 把这个缓冲区赋值给best_fit变量
n = n->rb_left;
} else if (size > buffer_size)
n = n->rb_right;
else {
best_fit = n;
break;
}
}
if (best_fit == NULL) {
printk(KERN_ERR "binder: %d: binder_alloc_buf size %zd failed, "
"no address space\n", proc->pid, size);
return NULL;
}
if (n == NULL) { // 到这里表示,n为null,但是best_fit不是null,说明有找到一个比n大的缓冲区
buffer = rb_entry(best_fit, struct binder_buffer, rb_node); // 获取这个缓冲区
buffer_size = binder_buffer_size(proc, buffer); // 获取缓冲区大小
}
if (binder_debug_mask & BINDER_DEBUG_BUFFER_ALLOC)
printk(KERN_INFO "binder: %d: binder_alloc_buf size %zd got buff"
"er %p size %zd\n", proc->pid, size, buffer, buffer_size);
// 现在buffer_size表示缓冲区的大小,算一下缓冲区结束地址对齐到边界后的值是多少,换句话说,has_page_addr就是缓冲区结束地址所在页的页基地址,注意是所在页面,即这个值是小于等于结束地址的值的
has_page_addr =
(void *)(((uintptr_t)buffer->data + buffer_size) & PAGE_MASK);
if (n == NULL) {
if (size + sizeof(struct binder_buffer) + 4 >= buffer_size) // 现在buffer_size表示实际分配给目标进程的内存有多大。size是需要的数据的大小
buffer_size = size; /* no room for other buffers */ // 如果缓冲区总大小buffer_size比需要的多出不到4字节,那么就把缓冲区全部分配给目标进程,注意后面会判断buffer_size和size是否相等来决定有没有分割这里的缓冲区
else
buffer_size = size + sizeof(struct binder_buffer); // 如果分配完后,剩余的还大于4字节,就需要多少给多少
}
// PAGE_ALIGN宏是把地址对齐后所在页面下一个页面的起始位置。由于上面buffer_size是实际分配的缓冲区大小,现在计算下,实际分配后,结束位置所在页面的起始地址
end_page_addr =
(void *)PAGE_ALIGN((uintptr_t)buffer->data + buffer_size);
// 上面分析了,has_page_addr是缓冲区结束地址所在页面的基地址,而end_page_addr是实际分配缓冲区后所在页面的下一个页面的基地址,也就是说,只有当实际分配的结束地址和缓冲区的结束地址在同一个页面的时候才会进入这个分支,这个时候我们把结束地址切到缓冲区所在页面的基地址。下面要开始分配内存了。
if (end_page_addr > has_page_addr)
end_page_addr = has_page_addr;
if (binder_update_page_range(proc, 1,
(void *)PAGE_ALIGN((uintptr_t)buffer->data), end_page_addr, NULL)) // 分配物理页内存
return NULL;
rb_erase(best_fit, &proc->free_buffers); // 从进程的内核空闲缓冲区队列红黑树中删除这个缓冲区结点
buffer->free = 0; //把这个缓冲区设置为正在使用
binder_insert_allocated_buffer(proc, buffer); // 把这个缓冲区加入到已经分配的缓冲区红黑树中
if (buffer_size != size) { // 如果实际分配的和缓冲区大小不一样,说明缓冲区还有剩余的没有分配
struct binder_buffer *new_buffer = (void *)buffer->data + size; // 把data起始位置前移到跳过实际分配的数据的大小
list_add(&new_buffer->entry, &buffer->entry); // 插入到该进程所有的缓冲区队列中,即&proc->buffers
new_buffer->free = 1; // 设置为空闲
binder_insert_free_buffer(proc, new_buffer); // 插入到空闲红黑树中
}
if (binder_debug_mask & BINDER_DEBUG_BUFFER_ALLOC)
printk(KERN_INFO "binder: %d: binder_alloc_buf size %zd got "
"%p\n", proc->pid, size, buffer);
buffer->data_size = data_size; // 设置缓冲区数据大小
buffer->offsets_size = offsets_size; // 设置缓冲区偏移数组大小
buffer->async_transaction = is_async; // 是否是异步的
if (is_async) { // 如果是异步的话
proc->free_async_space -= size + sizeof(struct binder_buffer); // 进程的异步缓冲区空间会减去这次分配的大小
if (binder_debug_mask & BINDER_DEBUG_BUFFER_ALLOC_ASYNC)
printk(KERN_INFO "binder: %d: binder_alloc_buf size %zd "
"async free %zd\n", proc->pid, size,
proc->free_async_space);
}
return buffer;
}
```
首先rb_node *n = proc->free_buffers.rb_node这句话,我们获得一个进程上空闲的缓冲区的根结点。每个进程都会把他空闲的内存保存在一颗红黑树上,这里就是从这可红黑树上获取结点,然后下面有个while循环会遍历每个节点,然后通过binder_buffer_size方法获取这个节点对应的内存大小,我们看下这个方法:
```c
static size_t binder_buffer_size( // 返回现在这个buffer的数据大小,proc中保存了当前进程相关的缓冲区等等的数据
struct binder_proc *proc, struct binder_buffer *buffer)
{
if (list_is_last(&buffer->entry, &proc->buffers)) // 如果当前要加入空闲内核缓冲区队列的这块缓冲块是内核缓冲块列表中的最后一个
return proc->buffer + proc->buffer_size - (void *)buffer->data; // 那么这块缓冲区大小就 = 内核缓冲区队列地址最后 - 这块缓冲区有效数据保存地址开始(即data字段)
else
return (size_t)list_entry(buffer->entry.next,
struct binder_buffer, entry) - (size_t)buffer->data; // 下一个buffer的基地址 - 现在这个buffer的data字段的地址 = 现在data里面数据的大小,即现在这个缓冲区大小
}
```
这个方法就是根据当前缓冲区后面一个缓冲区的地址减去当前缓冲区实际保存数据的位置,当前这个还根据是不是最后一个缓冲区做了处理,可以看下注释就明白了。我们回到前面binder_alloc_buf方法。
如果没找到这个缓冲区就返回,如果找到了就把这个缓冲区保存在一个结构体binder_buffer中:
```c
struct binder_buffer { //给进程用的内核缓冲区
struct list_head entry; /* free and allocated entries by addesss */
struct rb_node rb_node; /* free entry by size or allocated entry */ // 内核缓冲区列表中的一个节点
/* by address */
unsigned free : 1; // 如果free为1,表示空闲缓冲区的节点,否则表示正在使用
unsigned allow_user_free : 1; // 该缓冲区运行用户释放
unsigned async_transaction : 1; // 如果是一个异步事务,置1
unsigned debug_id : 29; // 标识一个内核缓冲区身份,调试用的
struct binder_transaction *transaction; // 内核缓冲区交给哪个事务使用
struct binder_node *target_node; // 内核缓冲区交给哪个binder实体对象使用
size_t data_size; // 缓冲区大小
size_t offsets_size; // 偏移数组的大小,偏移数组的每个值,记录了每个binder对象在缓冲区的位置
uint8_t data[0]; // 数据保存的地方,数据包括普通数据和binder对象
};
```
这个结构体除了记录这个缓冲区本身的一些信息外,还描述了交给了哪个事务,哪个binder实体对象使用等信息。我们回到前面的方法。
需要注意的是在操作系统中,分配内存一般是按照页来分配的,一页一般是4KB,所以如果需要的内存不大于4KB,那么系统就会分配给4KB,大于4KB的话,会分配给4KB的整数倍,下面的代码就计算下一个整页的内存地址是多少,最后调用binder_update_page_range这个方法来分配物理内存:
```c
// 为指定虚拟地址空间分配或者释放物理页面。 参数1:目标进程 参数2:1表示分配物理页面,0表示是否物理页面 参数3,4,开始结束地址 参数5:映射的用户空间地址
// 这里start是内核缓冲区虚拟开始地址,end是内核缓冲区虚拟结束地址。这个start和end都需要页对齐,即4K对齐
static int binder_update_page_range(struct binder_proc *proc, int allocate,
void *start, void *end, struct vm_area_struct *vma)
{
void *page_addr;
unsigned long user_page_addr;
struct vm_struct tmp_area;
struct page **page;
struct mm_struct *mm;
if (binder_debug_mask & BINDER_DEBUG_BUFFER_ALLOC)
printk(KERN_INFO "binder: %d: %s pages %p-%p\n",
proc->pid, allocate ? "allocate" : "free", start, end);
if (end <= start)
return 0;
if (vma) // 如果用户空间有数据,就用不到mm。mm是进程所在空间的内存信息
mm = NULL;
else
mm = get_task_mm(proc->tsk); // 如果用户空间没数据,就调用get_task_mm获取用户空间的内存信息
if (mm) {
down_write(&mm->mmap_sem);
vma = proc->vma; // 如果vma空就是从proc->vma取出赋值给vma,如果proc->vma也是空,下面会报错
}
if (allocate == 0)
goto free_range;
if (vma == NULL) {
printk(KERN_ERR "binder: %d: binder_alloc_buf failed to "
"map pages in userspace, no vma\n", proc->pid);
goto err_no_vma;
}
// 这里开始是分配内存
for (page_addr = start; page_addr < end; page_addr += PAGE_SIZE) { // 从内核地址开始,每4KB分配一个物理页
int ret;
struct page **page_array_ptr; //
// page_addr - proc->buffer是当前地址和开头相差多少字节,除以PAGE_SIZE后,就是数组的第几个,proc->buffer是缓冲区虚拟地址的开始地址
// page是指针的指针,所以page指向的是数组元素的地址,所以下面我们需要修改page指向地方的地址,就可以改变page的指向
page = &proc->pages[(page_addr - proc->buffer) / PAGE_SIZE]; // 获取存储物理页面的数组。proc->buffer是整个缓冲区的开始地址,page_addr是其中的一段
BUG_ON(*page);
*page = alloc_page(GFP_KERNEL | __GFP_ZERO); // 获取物理页面的地址保存在page指向的地方,即*page
if (*page == NULL) {
printk(KERN_ERR "binder: %d: binder_alloc_buf failed "
"for page at %p\n", proc->pid, page_addr);
goto err_alloc_page_failed;
}
tmp_area.addr = page_addr; // 该页的内核虚拟起始地址
tmp_area.size = PAGE_SIZE + PAGE_SIZE /* guard page? */; // 虽然每次循环都是1页的大小,即4KB,但是linux规定在内核物理地址空间需要再后面添加一块地址空间来做保护,先不用管那么多,按照这样来就行
page_array_ptr = page; // 物理地址
ret = map_vm_area(&tmp_area, PAGE_KERNEL, &page_array_ptr); // 把内核虚拟地址tmp_area和物理地址page_array_ptr进行映射
if (ret) {
printk(KERN_ERR "binder: %d: binder_alloc_buf failed "
"to map page at %p in kernel\n",
proc->pid, page_addr);
goto err_map_kernel_failed;
}
user_page_addr =
(uintptr_t)page_addr + proc->user_buffer_offset; // 用户虚拟地址开始位置 = 内核虚拟地址开始+偏移值
ret = vm_insert_page(vma, user_page_addr, page[0]); // 把物理地址映射到用户进程空间,这里参数一vma是用户进程空间的内存信息,包括虚拟地址开始结束位置等,参数二是这次映射的用户虚拟起始地址,参数3是物理地址,在进行映射的时候会修改用户空间的页表等信息,前2个信息在验证和写入页表时候会用到
if (ret) {
printk(KERN_ERR "binder: %d: binder_alloc_buf failed "
"to map page at %lx in userspace\n",
proc->pid, user_page_addr);
goto err_vm_insert_page_failed;
}
/* vm_insert_page does not seem to increment the refcount */
}
if (mm) {
up_write(&mm->mmap_sem);
mmput(mm);
}
return 0;
free_range:
.........................
return -ENOMEM;
}
```
这里vma是用户进程空间的虚拟地址信息,如果是空的话会从进程的vma字段获取。然后就是for循环的变量了,由于我们之前传入的参数已经知道了需要分配的起始页和结束页的地址,所以这里以页为单位,分配物理内存。这里记得之前说mmap方法时,有说过我们在mmap的时候,记录了内核和用户空间地址的一个差值,现在由于我们这里已经知道了用户空间的地址值,所以根据这个差值内核空间的地址值夜自然知道了,这样内核就可以直接读写用户空间的数据了。最后通过vm_insert_page这个方法映射到用户空间,这个方法太底层了。就不贴代码了,所谓映射就是在一个进程的页目录和页表中,记录下这个进程的虚拟地址,然后再让这个虚拟地址指向一个物理页面,这样每个进程就可以通过自己的虚拟地址来找到物理地址了。
回到binder_alloc_buf这个方法,在进行完内存的分配后,在做一些缓冲区的扫尾工作,比如把已经分配的缓冲区从进程的空闲缓冲区中删除,如果有剩余的缓冲区,需要重新加入空闲缓冲区,最后把这个申请的缓冲区返回到binder_transaction方法中,这样一个事务项binder_transaction就有了缓冲区,接下去可以进行读写了。继续看后面的代码:
```c
offp = (size_t *)(t->buffer->data + ALIGN(tr->data_size, sizeof(void *))); // 偏移数组的开始位置
// copy数据区到工作项的数据区。这里tr虽然在内核区,但是data里面缓冲区的数据还在用户区,所以要用copy_from_user
if (copy_from_user(t->buffer->data, tr->data.ptr.buffer, tr->data_size)) {
binder_user_error("binder: %d:%d got transaction with invalid "
"data ptr\n", proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
goto err_copy_data_failed;
}
// copy偏移数组到工作项数据区,同理上面tr虽然在内核,但是tr里面缓冲区偏移数组地址还是用户区的,所以要用copy_from_user
if (copy_from_user(offp, tr->data.ptr.offsets, tr->offsets_size)) {
binder_user_error("binder: %d:%d got transaction with invalid "
"offsets ptr\n", proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
goto err_copy_data_failed;
}
if (!IS_ALIGNED(tr->offsets_size, sizeof(size_t))) { // 貌似是校验是否边界对齐
binder_user_error("binder: %d:%d got transaction with "
"invalid offsets size, %zd\n",
proc->pid, thread->pid, tr->offsets_size);
return_error = BR_FAILED_REPLY;
goto err_bad_offset;
}
off_end = (void *)offp + tr->offsets_size; // 偏移数组结束位置
for (; offp < off_end; offp++) { // 遍历数据区,取出binder对象
struct flat_binder_object *fp;
if (*offp > t->buffer->data_size - sizeof(*fp) || // 当前缓冲区指针到末尾的距离不到一个flat_binder_object大小
t->buffer->data_size < sizeof(*fp) || // 缓冲区的大小不到一个flat_binder_object大小
!IS_ALIGNED(*offp, sizeof(void *))) {
binder_user_error("binder: %d:%d got transaction with "
"invalid offset, %zd\n",
proc->pid, thread->pid, *offp);
return_error = BR_FAILED_REPLY;
goto err_bad_offset;
}
// 取出binder对象,这里取出就是serive组件,目的是要建立他的实体对象,引用对象句柄等一些值
fp = (struct flat_binder_object *)(t->buffer->data + *offp);
switch (fp->type) {
........................
}
```
这里首先2个copy_from_user把用户空闲的数据和flat_binder_object对象的偏移数组复制到刚申请的目标进程的缓冲区中,由于这个数据缓冲区中保留着不止一个flat_binder_object对象,所以用一个for循环遍历取出,还记得当初flat_binder_object是怎么保存的吗,我们在看下调用方在生成这个对象时候的代码:
```c
status_t flatten_binder(const sp<ProcessState>& proc,
const sp<IBinder>& binder, Parcel* out) // 将一个service(JavaBBinder)组件封装成一个结构体
{
flat_binder_object obj;
obj.flags = 0x7f | FLAT_BINDER_FLAG_ACCEPTS_FDS;
if (binder != NULL) {
IBinder *local = binder->localBinder(); // 获取BBbinder,即服务端的service,本地对象
if (!local) {
...................
} else {
obj.type = BINDER_TYPE_BINDER;
obj.binder = local->getWeakRefs(); // 设置弱引用计数
obj.cookie = local; // 设置本地对象地址,由于同一个进程,直接可以获取本地对象地址
}
} else {
.............
}
return finish_flatten_binder(binder, obj, out);
}
```
我把无关的都删除了,这个看到type这个字段保存了BINDER_TYPE_BINDER这个值,cookie指向一个Jave层的JaveBBinder。好我们回到前面代码中,主要看下case是
BINDER_TYPE_BINDER这个值时候的处理:
```c
case BINDER_TYPE_BINDER: // 这个说明这个对象是注册到service manager中的
case BINDER_TYPE_WEAK_BINDER: {
struct binder_ref *ref;
// 获取实体对象,fp->binder应该是本地对象弱引用地址?
// 这里如果是注册到service manager的,获取的service便是一个server端的service组件
struct binder_node *node = binder_get_node(proc, fp->binder); // 获取service实体对象,第一次肯定是null
if (node == NULL) {
node = binder_new_node(proc, fp->binder, fp->cookie); // 新建立实体对象
if (node == NULL) {
return_error = BR_FAILED_REPLY;
goto err_binder_new_node_failed;
}
node->min_priority = fp->flags & FLAT_BINDER_FLAG_PRIORITY_MASK; // 设置优先级
node->accept_fds = !!(fp->flags & FLAT_BINDER_FLAG_ACCEPTS_FDS); // 设置是否允许携带文件描述符
}
if (fp->cookie != node->cookie) { // 验证一下,本地对象的地址是否正确。
binder_user_error("binder: %d:%d sending u%p "
"node %d, cookie mismatch %p != %p\n",
proc->pid, thread->pid,
fp->binder, node->debug_id,
fp->cookie, node->cookie);
goto err_binder_get_ref_for_node_failed;
}
// 在target_proc中创建一个引用对象来引用node,node是实体对象,比如要注册一个service到service manager,这里target_proc就是service manager
ref = binder_get_ref_for_node(target_proc, node);
if (ref == NULL) {
return_error = BR_FAILED_REPLY;
goto err_binder_get_ref_for_node_failed;
}
// 如果之前client传寄哪里是这个类型的,在已经传递给目标进程了,所以要修改成一下类型
if (fp->type == BINDER_TYPE_BINDER)
fp->type = BINDER_TYPE_HANDLE;
else
fp->type = BINDER_TYPE_WEAK_HANDLE;
fp->handle = ref->desc; // 把引用对象的句柄值设置给传进来时候的flat_binder_object
// 增加引用计数,这里增加引用对一些计数,后面binder_transaction_release会再减去
binder_inc_ref(ref, fp->type == BINDER_TYPE_HANDLE, &thread->todo);
if (binder_debug_mask & BINDER_DEBUG_TRANSACTION)
printk(KERN_INFO " node %d u%p -> ref %d desc %d\n",
node->debug_id, node->ptr, ref->debug_id, ref->desc);
} break;
```
这里首先调用binder_get_node方法,看下这个进程中是否已经有个这个服务的实体对象,第一次肯定是没有的,所以这里会返回空,不过我们还是看下这个方法:
```c
static struct binder_node *binder_get_node(struct binder_proc *proc, void __user *ptr)
{
struct rb_node *n = proc->nodes.rb_node; // 获取这个进程的所有实体对象
struct binder_node *node;
while (n) { // 遍历实体对象
node = rb_entry(n, struct binder_node, rb_node);
if (ptr < node->ptr)
n = n->rb_left;
else if (ptr > node->ptr)
n = n->rb_right;
else
return node;
}
return NULL;
}
```
这个方法也很好理解,就是每个进程都保存了所以该进程已经获得的实体对象,有的话则返回,没的话返回null。好了,回去继续。
如果前面返回空的话,会调用binder_new_node方法,创建实体对象:
```c
// 创建一个进程的实体对象返回,参数2是本地对象弱引用对象地址,参数3是本地对象地址
static struct binder_node *binder_new_node(struct binder_proc *proc, void __user *ptr, void __user *cookie)
{
struct rb_node **p = &proc->nodes.rb_node; // 进程的实体对象
struct rb_node *parent = NULL;
struct binder_node *node;
while (*p) { // 遍历进程的实体对象
parent = *p;
node = rb_entry(parent, struct binder_node, rb_node); // 取出实体对象
if (ptr < node->ptr) // 寻找是否有需要的实体对象
p = &(*p)->rb_left;
else if (ptr > node->ptr)
p = &(*p)->rb_right;
else
return NULL; // 如果找到就返回一个null给调用者,因为前面调用的地方接受到null就退出提示已经创建过了
}
node = kzalloc(sizeof(*node), GFP_KERNEL); // 到这里,就说明没有找到实体对象,创建之
if (node == NULL)
return NULL;
binder_stats.obj_created[BINDER_STAT_NODE]++;
rb_link_node(&node->rb_node, parent, p); // 插入进程实体对象红黑树
rb_insert_color(&node->rb_node, &proc->nodes); // 染色调整
node->debug_id = ++binder_last_id; // 调试用的标志
node->proc = proc; // 实体对象的宿主进程,即service进程
node->ptr = ptr; // 实体对象的本地对象弱引用计数地址
node->cookie = cookie; // 实体对象的本地对象的地址
node->work.type = BINDER_WORK_NODE; //实体对象的工作项,一般创建后这个工作项是用来设置引用计数的
INIT_LIST_HEAD(&node->work.entry); // 初始化工作项队列
INIT_LIST_HEAD(&node->async_todo); // 初始化异步任务队列
if (binder_debug_mask & BINDER_DEBUG_INTERNAL_REFS)
printk(KERN_INFO "binder: %d:%d node %d u%p c%p created\n",
proc->pid, current->pid, node->debug_id,
node->ptr, node->cookie);
return node; // 返回实体对象
}
```
这里首先还是遍历下注册进程中是否已经有了这个实体对象,如果没有的话,就创建一个binder_node对象,然后把他加入到注册进程的实体对象红黑树中,在把需要注册对象的进程,JavaBBinder对象地址等赋值给这里的binder_node对象然后返回。
我们知道实体对象是服务端在内核中的映射,同样客户端如果要找到实体对象也需要在内核中有个映射,这就是引用对象,所以这里再创建一个引用对象,用来指向实体对象,这样就能一直向上找到最终的服务了。创建引用对象方法如下:
```c
// 在target_proc中寻找一个是否引用了实体对象node的引用对象,没有的话就创建一个引用对象来引用node
static struct binder_ref *binder_get_ref_for_node(struct binder_proc *proc, struct binder_node *node)
{
struct rb_node *n;
struct rb_node **p = &proc->refs_by_node.rb_node;
struct rb_node *parent = NULL;
struct binder_ref *ref, *new_ref;
while (*p) { // 遍历进程的引用对象
parent = *p;
ref = rb_entry(parent, struct binder_ref, rb_node_node);
if (node < ref->node)
p = &(*p)->rb_left;
else if (node > ref->node)
p = &(*p)->rb_right;
else
return ref; // 找到和需要的实体对象一样的就返回
}
new_ref = kzalloc(sizeof(*ref), GFP_KERNEL); // 创建一个引用对象结构体
if (new_ref == NULL)
return NULL;
binder_stats.obj_created[BINDER_STAT_REF]++;
new_ref->debug_id = ++binder_last_id;
new_ref->proc = proc; // 设置client
new_ref->node = node; // 设置实体对象
rb_link_node(&new_ref->rb_node_node, parent, p); // 把该引用对象插入到client进程的红黑树
rb_insert_color(&new_ref->rb_node_node, &proc->refs_by_node);
new_ref->desc = (node == binder_context_mgr_node) ? 0 : 1; // 如果是service manager,句柄值设置为0,否则先设置为1
for (n = rb_first(&proc->refs_by_desc); n != NULL; n = rb_next(n)) { // 遍历进程的引用对象,设置一个最小未使用的值给new_ref
ref = rb_entry(n, struct binder_ref, rb_node_desc);
if (ref->desc > new_ref->desc)
break;
new_ref->desc = ref->desc + 1;
}
p = &proc->refs_by_desc.rb_node;
while (*p) { // 重新校验一下
parent = *p;
ref = rb_entry(parent, struct binder_ref, rb_node_desc);
if (new_ref->desc < ref->desc)
p = &(*p)->rb_left;
else if (new_ref->desc > ref->desc)
p = &(*p)->rb_right;
else
BUG();
}
rb_link_node(&new_ref->rb_node_desc, parent, p); // 插入进程的引用对象红黑树
rb_insert_color(&new_ref->rb_node_desc, &proc->refs_by_desc);
if (node) {
hlist_add_head(&new_ref->node_entry, &node->refs); // 把这个新建立的引用对象插入对应实体对象的引用对象列表中
if (binder_debug_mask & BINDER_DEBUG_INTERNAL_REFS)
printk(KERN_INFO "binder: %d new ref %d desc %d for "
"node %d\n", proc->pid, new_ref->debug_id,
new_ref->desc, node->debug_id);
} else {
if (binder_debug_mask & BINDER_DEBUG_INTERNAL_REFS)
printk(KERN_INFO "binder: %d new ref %d desc %d for "
"dead node\n", proc->pid, new_ref->debug_id,
new_ref->desc);
}
return new_ref;
}
```
首先在目标进程中遍历,看有没有这个引用对象,如果有则返回,没有则创建一个binder_ref对象,然后把目标进程和实体对象赋值给他。这里这个binder_ref还有一个句柄值,这个句柄值就是这个引用对象在客户端进程中红黑树上的关键字。我们知道客户端进程所有的引用对象也会保留在一颗红黑树上,这里每个节点的关键字就是他的句柄,这个引用对象还被加入到对应的实体对象中,这样客户端只要提供这个关键字就可以找到这个引用对象了,从而一路找到最终的服务。
## 添加事务到目标进程队列
回到方法binder_transaction,当前我们这个case是BINDER_TYPE_BINDER,线程处理完了,把type字段修改为BINDER_TYPE_HANDLE,最后把前面的引用对象的句柄值赋值给flat_binder_object对象的handle变量。这段代码分析好了,我们继续看后面还有一段代码:
```c
if (reply) {
..............
} else if (!(t->flags & TF_ONE_WAY)) { // 如果是一个同步的进程间通信请求
BUG_ON(t->buffer->async_transaction != 0);
t->need_reply = 1; // 设置需要回复
t->from_parent = thread->transaction_stack; // 该事务的前一个事务设置为原线程的事务栈
thread->transaction_stack = t; // 压入原(client)线程的事务栈中
} else {
.................
}
// getservice的时候,这里会发给client,通知他给他一个service的引用句柄,让client创建server的代理对象,即回到client的getService中
t->work.type = BINDER_WORK_TRANSACTION;
// 添加事务到进程,线程的todo队列, 或者到实体对象的异步队列中。
// 这里记住&t->work.entry是一个binder_transaction下的binder_work下的list_head,后面在binder_thread_read会根据这个路径来取数据
list_add_tail(&t->work.entry, target_list); // 添加到目标进程尾部
tcomplete->type = BINDER_WORK_TRANSACTION_COMPLETE; // 这个工作项会回到用户空间通知用户已经接收到命令
list_add_tail(&tcomplete->entry, &thread->todo); // 添加一个事务完成工作项到线程队列
if (target_wait) // 等待队列非空,唤醒队列
wake_up_interruptible(target_wait);
return;
```
到这里做这个事务项的最后处理了,首先前面参数reply为0,所以进入后面的else if中,他的父事务是事务堆栈中的栈顶元素,然后把这个事务压入栈顶。然后把这个事务的type修改为BINDER_WORK_TRANSACTION,后面处理这个事务的时候会根据这个case来选择进入分支,之后就把这个事务插入到目标队列中,等待目标进程来处理。
由于目前是在binder驱动中,现在已经处理完了客户端的请求,并且已经把任务发到服务端进程的队列中了,所以还需要通知下客户端我们已经处理完毕了,所以tcomplete这个事务项就是通知客户端的,把他的type设置为BINDER_WORK_TRANSACTION_COMPLETE,同时把插入到客户端的todo队列中。
## 回复客户端
最后如果目标进程等待队列target_wait不空,说明目前处于阻塞状态,唤醒他,让他继续处理后续工作。好了至此注册工作的第一步处理完了,注册任务已经在目标进程的待处理队列中了,也就是等待service manager来处理了。这个我们稍后再看,客户端这边后续还有些扫尾工作。这里的方法执行完后,会先回到binder_thread_write,然后这个方法也没什么执行的了,再回到binder_ioctl,我们看下之前执行到哪里:
```c
.....
switch (cmd) {
case BINDER_WRITE_READ: {
.................
if (bwr.write_size > 0) {
.................
ret = binder_thread_write(.........)
......
}
if (bwr.read_size > 0) {
.............
ret = binder_thread_read(.....)
.........
}
}
..........
}
..........
```
之前执行了binder_thread_write后,一路返回,现在开始执行读缓冲区了,由于之前binder驱动有提供读缓冲区,所以这边bwr.read_size > 0是成立的,所以接下去开始执行binder_thread_read方法:
```c
// 进程希望从binder中收到数据,所以会不断调用这个方法检查是否自己的todo种(包括进场todo和线程todo)有新任务,如果有该方法会解析并且把用户需要的数据写入用户缓冲区,然后返回给用户
// 在这个方法前,binder应该已经把任务写入的实体对象的todo或者他线程池中的线程的todo中,server或client进场会不断遍历他们,调用下面方法,把用户进程缓冲区地址传入后陷入内核态,然后执行完后返回用户态,读取数据来执行
static int binder_thread_read(struct binder_proc *proc, struct binder_thread *thread,
void __user *buffer, int size, signed long *consumed, int non_block)
{
void __user *ptr = buffer + *consumed; // 用户缓冲区的起始地址
void __user *end = buffer + size; // 用户缓冲区的结束位置
int ret = 0;
int wait_for_proc_work;
if (*consumed == 0) { // 如果是缓冲区开始
if (put_user(BR_NOOP, (uint32_t __user *)ptr)) // 先写入一个固定空命令,表示开头
return -EFAULT;
ptr += sizeof(uint32_t);
}
retry:
wait_for_proc_work = thread->transaction_stack == NULL && list_empty(&thread->todo); // 没有当前线程需要处理的任务
if (thread->return_error != BR_OK && ptr < end) { //这里是做处理tracsation。death出错了,会先返回给用户
if (thread->return_error2 != BR_OK) {
if (put_user(thread->return_error2, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
if (ptr == end)
goto done;
thread->return_error2 = BR_OK;
}
if (put_user(thread->return_error, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
thread->return_error = BR_OK;
goto done;
}
thread->looper |= BINDER_LOOPER_STATE_WAITING; //线程马上要睡眠了,先把线程状态改为空闲
if (wait_for_proc_work) // 当前没有任务
proc->ready_threads++; // 就把空闲线程+1
mutex_unlock(&binder_lock);
if (wait_for_proc_work) { // 当前没有任务
if (!(thread->looper & (BINDER_LOOPER_STATE_REGISTERED |
BINDER_LOOPER_STATE_ENTERED))) {
binder_user_error("binder: %d:%d ERROR: Thread waiting "
"for process work before calling BC_REGISTER_"
"LOOPER or BC_ENTER_LOOPER (state %x)\n",
proc->pid, thread->pid, thread->looper);
wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2); // 线程中断休眠
}
binder_set_nice(proc->default_priority); // 设置优先级
if (non_block) { // 非阻塞可以接着执行
if (!binder_has_proc_work(proc, thread)) // 没有任务
ret = -EAGAIN;
} else // 阻塞的话,让进程在等待队列上
ret = wait_event_interruptible_exclusive(proc->wait, binder_has_proc_work(proc, thread));
} else { // 当前有任务
if (non_block) { // 非阻塞
if (!binder_has_thread_work(thread))
ret = -EAGAIN;
} else // 阻塞状态,放入线程等待队列
ret = wait_event_interruptible(thread->wait, binder_has_thread_work(thread));
}
mutex_lock(&binder_lock);
if (wait_for_proc_work) // 到这里说明可能有任务了(阻塞),但是也有可能EAGAIN(非阻塞)
proc->ready_threads--; // 之前如果是无任务的话,空闲ready_threads会++,所以现在阻塞返回了,需要把ready_threads--
thread->looper &= ~BINDER_LOOPER_STATE_WAITING; // 解除线程空闲状态
if (ret)
return ret;
................
}
```
开始的这部分代码也没什么多说的,主要就是不断的从对应进程或者线程中的todo队列获取任务,如果有就继续往下执行,否则就在这里阻塞住。由于刚才我们已经分析了,binder驱动往客户端这边的todo队列已经发送了一个事务,所以现在todo中是有任务的。需要注意的是,这里会先从线程的todo队列中寻找任务,如果没有还会调用binder_has_proc_work方法去进程中找:
```c
static int binder_has_proc_work(struct binder_proc *proc, struct binder_thread *thread) // 判断进程是否工作项
{
// 后面一个的意思是当前线程不可以睡眠,需要返回用户空间。可以作为没有工作项理解
return !list_empty(&proc->todo) || (thread->looper & BINDER_LOOPER_STATE_NEED_RETURN);
}
```
进程也是从todo中找,如果找到了就继续下面的执行,我们继续看后续的代码:
```c
switch (w->type) {
...........
case BINDER_WORK_TRANSACTION_COMPLETE: { // binder驱动返回给用户的命令
cmd = BR_TRANSACTION_COMPLETE;
if (put_user(cmd, (uint32_t __user *)ptr)) // 把这个通知写回到用户缓冲区中
return -EFAULT;
ptr += sizeof(uint32_t);
binder_stat_br(proc, thread, cmd); // 数据的统计
if (binder_debug_mask & BINDER_DEBUG_TRANSACTION_COMPLETE)
printk(KERN_INFO "binder: %d:%d BR_TRANSACTION_COMPLETE\n",
proc->pid, thread->pid);
list_del(&w->entry); // 从线程工作项链表中删除这个工作项
kfree(w); // 释放这个工作项
binder_stats.obj_deleted[BINDER_STAT_TRANSACTION_COMPLETE]++;
} break;
...............
}
```
这个case可以看到主要是把BR_TRANSACTION_COMPLETE这个命令写到用户提供的缓冲区中,然后在从todo队列中删除这个工作项目。
## 回到客户端
至此已经把返回的数据写回到用户缓冲区了,下面的流程会不断往回返回,一直返回到客户端进程的talkWithDriver方法,之前是在这里开始进程间通信的我们回到这个方法:
```c
status_t IPCThreadState::talkWithDriver(bool doReceive)
{
....................
if (err >= NO_ERROR) {
....................
if (bwr.read_consumed > 0) { //这个是binder驱动返回给用户的数据
mIn.setDataSize(bwr.read_consumed); // 设置数据的大小
mIn.setDataPosition(0); // 设置数据起始读的位置
}
............
return NO_ERROR;
}
.....................
}
```
回到这里可以看到客户端设置了数据的大小和读取的起始位置,然后继续往上返回到IPCThreadState::transact方法:
```c
status_t IPCThreadState::waitForResponse(Parcel *reply, status_t *acquireResult) // 向binder驱动发送命令,等待回复的结果
{
int32_t cmd;
int32_t err;
while (1) {
if ((err=talkWithDriver()) < NO_ERROR) break; // talkWithDriver向binder发送命令,正常返回0
err = mIn.errorCheck();
if (err < NO_ERROR) break;
if (mIn.dataAvail() == 0) continue; // 如果没有返回数据继续等待
cmd = mIn.readInt32();
..........
switch (cmd) {
case BR_TRANSACTION_COMPLETE: // 如果是一个binder驱动给的正常的回复,会重新执行这个while继续talkWithDriver执行
if (!reply && !acquireResult) goto finish;
break;
..........
}
..........
return err;
}
```
可以看到这个BR_TRANSACTION_COMPLETE什么也没做,由于外层是一个while循环,所以会再次进入talkWithDriver方法,从而等待新的任务,至此客户端这边第一次完整的一个进程间通信就完成了,我们先给个时序图,然后下一篇我们到服务端那边,看下service manager是怎么处理注册一个服务的任务的。
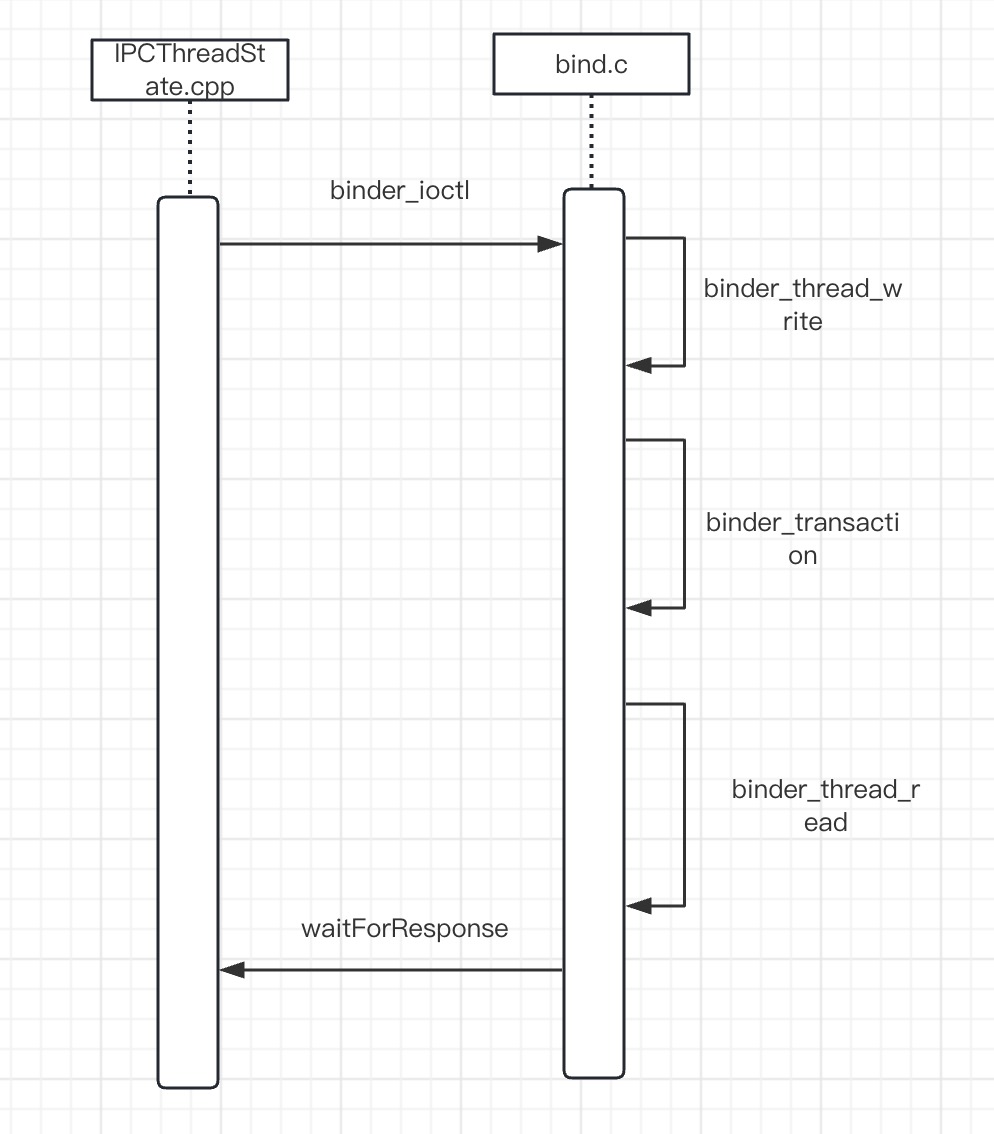

Android进程间通信Binder(四)