
第三篇文章讲到了addservice的客户端第一次进程间通信完成了,接下来轮到service manager执行任务了。还记得第一篇文章讲到service manager启动完成糊,最终阻塞在binder驱动的binder_thread_read方法中吗?具体可以去第一篇文章翻一下,我们这篇文章就接着第一篇文章讲,看service manager是怎么处理addservice的。
## service manager读取事务
回到binder_thread_read方法中:
```c
static int
binder_thread_read(struct binder_proc *proc, struct binder_thread *thread,
void __user *buffer, int size, signed long *consumed, int non_block)
{
...........
while (1) {
uint32_t cmd;
struct binder_transaction_data tr;
struct binder_work *w;
struct binder_transaction *t = NULL;
if (!list_empty(&thread->todo)) // 线程中待处理的工作项非空
w = list_first_entry(&thread->todo, struct binder_work, entry); //从线程待处理工作项链表中取出第一个工作项
else if (!list_empty(&proc->todo) && wait_for_proc_work) // 进程中有待处理的工作项,并且线程中没有带处理的工作项
w = list_first_entry(&proc->todo, struct binder_work, entry); // 从进程待处理工作项链表中取出第一个工作项
else {
if (ptr - buffer == 4 && !(thread->looper & BINDER_LOOPER_STATE_NEED_RETURN)) /* no data added */ // 没有工作项
goto retry;
break;
}
if (end - ptr < sizeof(tr) + 4) // 如果缓冲区剩余容量小于数据结构体+4字节,break
break;
switch (w->type) {
case BINDER_WORK_TRANSACTION: {
t = container_of(w, struct binder_transaction, work); // t指向一个binder_transaction
} break;
..........
}
...................
}
```
这个方法也是老熟人了,我们跳过前面之前重复的部分,从service manager获取工作项开始。上一篇文章讲到把一个工作项添加到的service manager的todo队列中,这里service manager就从todo队列开始取数据,取出来后,由于这个工作项类型是BINDER_WORK_TRANSACTION,所以调用container_of方法。这里w是一个工作项binder_work,他在保存在binder_transaction上了,所以可以通过container_of方法取出binder_transaction,并赋值给t。接着看后面的代码:
```c
if (t->buffer->target_node) {
// 这里取出实体对象。如果是service manager的话是binder_context_mgr_node
// 注意这里开始给binder_transaction_data赋值,这里赋值的结果最终会在service manager的binder_loop方法中的binder_parse方法
// 中被转为binder_txn类,binder_txn和进入这个分支对应的数据字段正好对应
struct binder_node *target_node = t->buffer->target_node; // 取出实体对象
tr.target.ptr = target_node->ptr; // service引用计数对象
tr.cookie = target_node->cookie; // service地址
t->saved_priority = task_nice(current); // 把目标线程优先级先保存下,以便用完后恢复
if (t->priority < target_node->min_priority &&
!(t->flags & TF_ONE_WAY)) // 目标线程可以理解成是替发起进程来做事情的,所以t->priority是原线程的优先级大于目标线程的话
binder_set_nice(t->priority); // 设置目标线程优先级为原线程
else if (!(t->flags & TF_ONE_WAY) || // 如果是同步通信
t->saved_priority > target_node->min_priority) // 或者是异步同步,但是目标线程优先级小于目标线程要求最低优先级。注意,异步的话线程不需要返回,所以没有优先级要求,但是要满足目标线程的最低优先级
binder_set_nice(target_node->min_priority); // 则把目标线程优先级设置为最低要求的优先级
cmd = BR_TRANSACTION;
} else { // 没有实体对象情况,比如server向client回复时候
tr.target.ptr = NULL;
tr.cookie = NULL;
cmd = BR_REPLY;
}
tr.code = t->code; // 赋值命令
tr.flags = t->flags; // 赋值是否允许包含文件描述符
tr.sender_euid = t->sender_euid;
if (t->from) { // 如果有client发起事务的线程
struct task_struct *sender = t->from->proc->tsk; // 获取原进程的进程任务块
tr.sender_pid = task_tgid_nr_ns(sender, current->nsproxy->pid_ns); // 获取线程组ID
} else {
tr.sender_pid = 0;
}
tr.data_size = t->buffer->data_size; // 赋值缓冲区大小
tr.offsets_size = t->buffer->offsets_size; // 赋值缓冲区偏移数组大小
tr.data.ptr.buffer = (void *)t->buffer->data + proc->user_buffer_offset; // 保存缓冲区中的数据
tr.data.ptr.offsets = tr.data.ptr.buffer + ALIGN(t->buffer->data_size, sizeof(void *)); // 保存偏移数组
if (put_user(cmd, (uint32_t __user *)ptr)) // 把命令复制到用户空间的缓冲区
return -EFAULT;
ptr += sizeof(uint32_t);
if (copy_to_user(ptr, &tr, sizeof(tr))) // 把数据复制到用户空间的缓冲区
return -EFAULT;
ptr += sizeof(tr);
..................
list_del(&t->work.entry); // 删除这个工作项
t->buffer->allow_user_free = 1; // 允许用户释放该缓冲区,这个buffer应该是client这边的内核缓冲区
if (cmd == BR_TRANSACTION && !(t->flags & TF_ONE_WAY)) { // 如果是一个同步进程通信
t->to_parent = thread->transaction_stack; // 当前这个事务的父事务变成,目标线程的事务栈顶
t->to_thread = thread; // 处理这个事务的线程也改成目标线程,也即原来在wirte的时候是client线程,现在变为server线程了
thread->transaction_stack = t; // 目标线程事务的栈顶改为这个事务
} else {
.................
}
......................
```
这里从事务项的缓冲区中取出实体对象,这里是指service namager的实体对象。然后由于前面声明了一个binder_transaction_data结构体,所以接下去要拼装这个结构体。从事务项中取出目标进程service manager,然后把地址赋值给binder_transaction_data结构体,然后再取出事务项的缓冲区,这里的缓冲区就是在目标进程service manager上的。最后通过put_user函数把cmd复制到缓冲区,copy_to_user函数把binder_transaction_data复制到缓冲区。这里主要传递的就是binder_transaction_data这个结构体,这个结构体的缓冲区就是目标进程和内核共享的内存区域,这个在后面还会说到,这个把这个缓冲区的地址转化为用户进程的地址是通过proc->user_buffer_offset这个偏移值来转化的,还记得之前在内存映射时候说过的偏移值吗,用户进程和内核进程的共享内存区域相差一个固定值,就是用在这种需要转换的地方的。
这段代码后面还有一个地方需要注意:
```c
t->to_parent = thread->transaction_stack;
t->to_thread = thread;
thread->transaction_stack = t
```
这里的三句代码是把这个事务项压入了目标进程的栈,并且是放到了栈顶。这个后面还会取出来用,到后面我们再说。
## 回到service manager进程
到这里阻塞在binder驱动中的service manager就读取数据了,接着会返回到自己的进程中,即回到binder_loop方法中:
```c
void binder_loop(struct binder_state *bs, binder_handler func) // service循环等待client请求
{
......................
for (;;) {
...............
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr); // 把缓冲区传入ioctl中,通过BINDER_WRITE_READ命令检查是否有新的进程
if (res < 0) {
LOGE("binder_loop: ioctl failed (%s)\n", strerror(errno));
break;
}
res = binder_parse(bs, 0, readbuf, bwr.read_consumed, func); // 解析binder驱动返回的数据,添加service等操作
.................
}
}
```
还记得之前我们是调用ioctl这个方法的,现在回来了,接着执行binder_parse方法:
```c
int binder_parse(struct binder_state *bs, struct binder_io *bio,
uint32_t *ptr, uint32_t size, binder_handler func) // ptr是binder驱动返回的缓冲区
{
int r = 1;
uint32_t *end = ptr + (size / 4); // size是字节,这里遍历的时候设置为32位
while (ptr < end) {
uint32_t cmd = *ptr++;
.........
switch(cmd) {
.........
case BR_TRANSACTION: { // 接受其他进程通过binder驱动给service manager的请求
// 获得缓冲区数据,这里和之前在binder_thread_read中设置的binder_transaction_data对应
struct binder_txn *txn = (void *) ptr;
if ((end - ptr) * sizeof(uint32_t) < sizeof(struct binder_txn)) {
LOGE("parse: txn too small!\n");
return -1;
}
binder_dump_txn(txn); // 打印一些txn的数据
if (func) {
unsigned rdata[256/4];
struct binder_io msg;
struct binder_io reply;
int res;
bio_init(&reply, rdata, sizeof(rdata), 4); // 初始化reply,用来后面返回给binder驱动用
bio_init_from_txn(&msg, txn); // 初始化msg,用txn种数据初始化msg
res = func(bs, txn, &msg, &reply); // 调用func方法,即svcmgr_handler,注册组件到service manager中等
binder_send_reply(bs, &reply, txn->data, res); // 向其他进程回复
}
ptr += sizeof(*txn) / sizeof(uint32_t);
break;
}
..........
}
return r;
}
```
这个方法这里首先取了cmd,从前面在binder驱动中的赋值可以知道,他的值是BR_TRANSACTION,所以这里就截取了这段代码。这里有个结构体binder_txn,他其实和binder_transaction_data是一样的,只不过由于binder_transaction_data中有联合体,这个把联合体去掉了,所以简洁了。这个结构体保存了需要解析的数据,所以下面会传到解析的方法中。另外还定义了2个变量,一个是reply,一个是msg,reply是用户后面会返回给binder驱动用的,msg是把前面binder_txn中的缓冲区单独保存到这里,也是需要传给解析方法的。我们看下binder_io结构体:
```c
struct binder_io // 类似于Parcel
{
char *data; /* pointer to read/write from */ // 指向当前数据缓冲区
uint32_t *offs; /* array of offsets */ // 指向当前偏移数组
uint32_t data_avail; /* bytes available in data buffer */ // 数据区还有多少内容未被解析(或者还有多少空间可以获取)
uint32_t offs_avail; /* entries available in offsets array */ // 偏移数组还有多少个未被解析(或者还有多少空间可以获取)
char *data0; /* start of data buffer */ // 指向当前数据缓冲区开始位置
uint32_t *offs0; /* start of offsets buffer */ // 指向当前偏移数组开始位置
uint32_t flags; //
uint32_t unused;
};
```
可以看到这个结构体主要就是保留缓冲区有关的。然后看下reply的初始化:
```c
void bio_init(struct binder_io *bio, void *data,
uint32_t maxdata, uint32_t maxoffs) // maxoffs表示偏移数组在缓冲区的个数
{
uint32_t n = maxoffs * sizeof(uint32_t); // 每个偏移数组是一个int,n是偏移数组一共有多大
if (n > maxdata) { // 偏移数组大于了缓冲区大小,报错
bio->flags = BIO_F_OVERFLOW;
bio->data_avail = 0;
bio->offs_avail = 0;
return;
}
bio->data = bio->data0 = data + n; // 数据区开始位置是开始跳过n个?
bio->offs = bio->offs0 = data; // 偏移数据开始位置是开头?
bio->data_avail = maxdata - n; // 数据区最大字节数
bio->offs_avail = maxoffs; // 偏移数组最大个数
bio->flags = 0;
}
```
可以看到这里的数据区开头是准备写入偏移数组的,由于这里maxoffs传入的时候是4,所以缓冲区中最多可以有4个binder对象。然后数据就紧跟着这里的偏移数组。
下面在看下msg的初始化:
```c
void bio_init_from_txn(struct binder_io *bio, struct binder_txn *txn) // 把txn中数据设置到bio中
{
bio->data = bio->data0 = txn->data; // 数据区的开始地址
bio->offs = bio->offs0 = txn->offs; // 偏移数组的开始地址
bio->data_avail = txn->data_size; // 数据大小
bio->offs_avail = txn->offs_size / 4; // 偏移数组个数,由于偏移数组每个元素四字节,个数就要除以4
bio->flags = BIO_F_SHARED; // 缓冲区是内核和进程映射的
}
```
这里就比较简单,就是从binder驱动返回的数据中的缓冲区保存在msg上。
## 注册入口函数
好了接着就调用func(bs, txn, &msg, &reply)这个函数了,func是什么函数,这是在main函数里面调用的,我们回头再看下:
```c
........
binder_loop(bs, svcmgr_handler);
.........
```
可以看到这里调用的函数就是svcmgr_handler,我们跟进去看这个函数:
```c
// 添加service组件到service manager中,主要就是加一个已注册组件结构体,里面有字段指向service组件
int svcmgr_handler(struct binder_state *bs,
struct binder_txn *txn,
struct binder_io *msg,
struct binder_io *reply)
{
struct svcinfo *si;
uint16_t *s;
unsigned len;
void *ptr;
uint32_t strict_policy;
if (txn->target != svcmgr_handle)
return -1;
strict_policy = bio_get_uint32(msg); //这里获取头,但是没用,只不过调用bio_get_uint32方法会跳过32位
s = bio_get_string16(msg, &len); // len保存了字符串长度,s指向字符串
// 校验请求头,记得servie manager的addSevice方法中开始写入的writeInterfaceToken这个方法吗
if ((len != (sizeof(svcmgr_id) / 2)) || // 如果长度不一样退出
memcmp(svcmgr_id, s, sizeof(svcmgr_id))) { // 如果字符串比较不一样退出,一样是0
fprintf(stderr,"invalid id %s\n", str8(s));
return -1;
}
switch(txn->code) {
.............
// 注意是不是从来没有看到过这个枚举值啊,怎么突然冒出来的?记得addServic方法时候添加的是ADD_SERVICE_TRANSACTION吗,不好意思这个枚举值也是3。所以两者对上了。
case SVC_MGR_ADD_SERVICE: // 这个分支是把一个service组件注册到service manager
s = bio_get_string16(msg, &len); // s指向service名字的字符串
ptr = bio_get_ref(msg); //ptr是待注册的引用对象句柄值,可以理解为一个long数值
if (do_add_service(bs, s, len, ptr, txn->sender_euid)) // 在service manager中增加一个结构体给注册的service组件
return -1;
break;
...............
default:
LOGE("unknown code %d\n", txn->code);
return -1;
}
bio_put_uint32(reply, 0); // 把0写到reply中
return 0;
```
这里开始先做些请求头的校验,然后取出txn->code,这个code就是最开始注册时候的参数ADD_SERVICE_TRANSACTION,他是一个枚举值3,而这里SVC_MGR_ADD_SERVICE也是枚举值3,所以会进入这个case。
首先这个缓冲区中的值是当初addService时候值的顺序,还记得addService时候添加的值吗,我们在看一眼:
```c
public void addService(String name, IBinder service)
throws RemoteException {
Parcel data = Parcel.obtain(); // 向binder驱动请求的数据
Parcel reply = Parcel.obtain(); // binder返回的数据
data.writeInterfaceToken(IServiceManager.descriptor); // 写入请求头
data.writeString(name); // 写入service名字
data.writeStrongBinder(service); // 写入service,这里service实际上是JavaBBinder或者BpBInder
mRemote.transact(ADD_SERVICE_TRANSACTION, data, reply, 0); // 发送请求给binder驱动
reply.recycle();
data.recycle();
}
```
可以看到这里请求头后写入的就是service的名字,在往后其实就是一个本地对象。所以我们回到前面的方法依次取出service的名字和本地对象后调用do_add_service方法。
```c
int do_add_service(struct binder_state *bs,
uint16_t *s, unsigned len,
void *ptr, unsigned uid) // 注册service到service manager
{
struct svcinfo *si;
// LOGI("add_service('%s',%p) uid=%d\n", str8(s), ptr, uid);
if (!ptr || (len == 0) || (len > 127))
return -1;
if (!svc_can_register(uid, s)) { // 检查该进程是否有权限注册service
LOGE("add_service('%s',%p) uid=%d - PERMISSION DENIED\n",
str8(s), ptr, uid);
return -1;
}
si = find_svc(s, len); // 是否这个名字已经被注册了
if (si) { // 有这个组件了
if (si->ptr) { // 在检查下引用对象句柄值是否非0,是的话就return
LOGE("add_service('%s',%p) uid=%d - ALREADY REGISTERED\n",
str8(s), ptr, uid);
return -1;
}
si->ptr = ptr; // 没指向的话,设置指向
} else { // 没有被注册过
si = malloc(sizeof(*si) + (len + 1) * sizeof(uint16_t)); // 创建一个注册service组件,大小除了svcinfo本身+名字的大小
if (!si) {
LOGE("add_service('%s',%p) uid=%d - OUT OF MEMORY\n",
str8(s), ptr, uid);
return -1;
}
si->ptr = ptr; // 这个是引用对象句柄值,通过引用对象句柄值可以找到实体对象
si->len = len; // service名字长度
memcpy(si->name, s, (len + 1) * sizeof(uint16_t)); // 赋值service名字
si->name[len] = '\0';
si->death.func = svcinfo_death; // 设置service死亡时,调用的方法
si->death.ptr = si; // 死亡最贱的宿主设置为对应注册service组件结构体
si->next = svclist; // 添加到队头
svclist = si; // 当前切到队头
}
binder_acquire(bs, ptr); // 给service manager增加引用对象计数
binder_link_to_death(bs, ptr, &si->death);// 当注册的service死亡时候,给service manager增加死亡通知
return 0;
}
```
这个方法就是真正把一个服务注册到service manager中了。首先该方法会检查下该进程是否有权限注册,会调用svc_can_register这个方法,我们看下:
```c
int svc_can_register(unsigned uid, uint16_t *name) // 检查用户是否有权限注册service
{
unsigned n;
if ((uid == 0) || (uid == AID_SYSTEM)) // 0是root用户,AID_SYSTEM系统server用户 有资格注册service
return 1;
// 遍历allowed数组,只有uid和name符合的才有资格注册service
for (n = 0; n < sizeof(allowed) / sizeof(allowed[0]); n++)
if ((uid == allowed[n].uid) && str16eq(name, allowed[n].name))
return 1;
return 0;
}
```
如果是root用户,或者是系统用户,可以有注册的权限。接着后面会遍历一个allowed数组,如果uid和name在这个数组里面那么也是可以注册的。这个我们了解下就可以,返回去看后面的。
首先我们先了解一下结构体svcinfo:
```c
struct svcinfo // 被注册了的service组件结构体
{
struct svcinfo *next; // 下一个svcinfo
void *ptr; // 引用对象的句柄值
struct binder_death death; // 死亡通知
unsigned len; // 长度
uint16_t name[0]; // 组件名字
};
```
可以看到这个结构体是一个链表,next字段指向下一个元素。ptr则指向一个注册的组件,name则是这个组件的名字。我们回到代码看这个结构体是怎么用的。首先通过find_svc这个方法看是否已经注册过这个服务:
```c
struct svcinfo *find_svc(uint16_t *s16, unsigned len) // 寻找是否名字为s16,长度len的service组件已经被注册了
{
struct svcinfo *si;
for (si = svclist; si; si = si->next) { // 遍历全局svcinfo表,比较长度和名字有没有一样的
if ((len == si->len) &&
!memcmp(s16, si->name, len * sizeof(uint16_t))) {
return si;
}
}
return 0;
}
```
这个方法很简单,就是变量这个链表,看有没有名字一样的,有就返回,没有返回0.我们回到前面方法,如果找到这个对象,我们把之前注册时候的组件弱引用值赋值给它,也就是一个JavaBBinder,即si->ptr = ptr这句话。如果没有找到的话会创建一个svcinfo结构体,然后也会把注册的组件复制给它。这个ptr是开始我们写入flat_binder_object对象中的binder字段,是个指针指向这个组件。我们在看一眼当初这个flat_binder_object创建时候的代码:
```c
status_t flatten_binder(const sp<ProcessState>& proc,
const sp<IBinder>& binder, Parcel* out)
{
flat_binder_object obj;
obj.flags = 0x7f | FLAT_BINDER_FLAG_ACCEPTS_FDS;
if (binder != NULL) {
IBinder *local = binder->localBinder(); // 获取BBbinder,即服务端的service,本地对象
if (!local) {
.............
} else {
obj.type = BINDER_TYPE_BINDER;
obj.binder = local->getWeakRefs();
obj.cookie = local;
}
} else {
..........
}
return finish_flatten_binder(binder, obj, out);
}
```
看到吗,就是这个binder的字段,是一个弱引用指针。
## 准备再次回到binder驱动
好了,最后这个新注册的组件就在service manager内部的的svcinfo结构体链表中作为一项存在。至此一个服务组件就被注册到了service manager中了。后面还有些扫尾工作我们回到svcmgr_handler方法中,还有剩余的代码:
```c
bio_put_uint32(reply, 0);
return 0;
```
这个把0写入reply缓冲区中,然后返回0,代表注册成功。这里再往上返回,一直到binder_parse方法中,还有一句代码:
```c
binder_send_reply(bs, &reply, txn->data, res);
```
这句代码也就是service manager处理完工作后,再次通知binder驱动,我们看下代码:
```c
// 处理完成,service manger通知binder驱动,把结果返回到client
void binder_send_reply(struct binder_state *bs,
struct binder_io *reply,
void *buffer_to_free,
int status)
{
struct {
uint32_t cmd_free;
void *buffer;
uint32_t cmd_reply;
struct binder_txn txn;
} __attribute__((packed)) data;
data.cmd_free = BC_FREE_BUFFER; // server处理完事务,用来通知binder驱动清理缓冲区
data.buffer = buffer_to_free;
data.cmd_reply = BC_REPLY; // 给client的回复
data.txn.target = 0;
data.txn.cookie = 0;
data.txn.code = 0;
if (status) { // 如果status不等于0,说明报错了,service manager处理失败了
data.txn.flags = TF_STATUS_CODE; // 出错码标识
data.txn.data_size = sizeof(int); // 数据大小应该也是一个整数
data.txn.offs_size = 0;
data.txn.data = &status; // 具体的出错码
data.txn.offs = 0;
} else { // 处理成功
data.txn.flags = 0;
data.txn.data_size = reply->data - reply->data0; // 返回给用户的数据大小
data.txn.offs_size = ((char*) reply->offs) - ((char*) reply->offs0); // 返回偏移数组的大小
data.txn.data = reply->data0; // 返回缓冲区的基址
data.txn.offs = reply->offs0; // 返回偏移数组的基址
}
binder_write(bs, &data, sizeof(data)); // 通知binder驱动,并传过去数据
}
```
这个方法我们看到有个内部的结构体,是返回给binder驱动的数据。我们看到这个结构体有2个命令,cmd_free这个的值是BC_FREE_BUFFER,代表通知binder驱动,我已经处理完毕了,之前开辟的缓冲区可以释放了。另一个cmd_reply的值是BC_REPLY,这个是项客户端发消息,通知客户端我已经注册成功了。然后在数据中还有之前写入的缓冲区数据。最后调用binder_write方法:
```c
int binder_write(struct binder_state *bs, void *data, unsigned len) // 调用ioctl进行读写
{
struct binder_write_read bwr;
int res;
bwr.write_size = len; // 这里3个是输入缓冲区
bwr.write_consumed = 0;
bwr.write_buffer = (unsigned) data; // 设置输入缓冲区
bwr.read_size = 0; // 这里3个是输出缓冲区,这里读缓冲区设置为0,这样写写入命令后,就不会在binder驱动中等待了,会回到用户空间
bwr.read_consumed = 0;
bwr.read_buffer = 0;
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
if (res < 0) {
fprintf(stderr,"binder_write: ioctl failed (%s)\n",
strerror(errno));
}
return res;
}
```
这里看到只有写缓冲区,没有读缓冲区,说明这次service manager向binder请求后就不需要回复了。然后我们又见到了熟悉的ioctl方法,命令是BINDER_WRITE_READ,这个应该看过前面文章的同学都很熟悉了吧,我们直接切到binder驱动那里binder_thread_write方法:
```c
case BC_FREE_BUFFER: { // 通知binder可以释放对应进程的内核缓冲区
void __user *data_ptr;
struct binder_buffer *buffer;
if (get_user(data_ptr, (void * __user *)ptr)) // 指向在用户空间的内核缓冲区
return -EFAULT;
ptr += sizeof(void *);
buffer = binder_buffer_lookup(proc, data_ptr); // 在进程中的已经分配的缓冲区树中查找是否有这个缓冲区
if (buffer == NULL) { // 没找到退出
binder_user_error("binder: %d:%d "
"BC_FREE_BUFFER u%p no match\n",
proc->pid, thread->pid, data_ptr);
break;
}
if (!buffer->allow_user_free) { // 不允许用户进程释放,退出
binder_user_error("binder: %d:%d "
"BC_FREE_BUFFER u%p matched "
"unreturned buffer\n",
proc->pid, thread->pid, data_ptr);
break;
}
if (binder_debug_mask & BINDER_DEBUG_FREE_BUFFER)
printk(KERN_INFO "binder: %d:%d BC_FREE_BUFFER u%p found buffer %d for %s transaction\n",
proc->pid, thread->pid, data_ptr, buffer->debug_id,
buffer->transaction ? "active" : "finished");
// 这个缓冲区是否被分配给一个事务处理了,一般要清缓冲区了,说明事务都完成了,所以下面也都清0
if (buffer->transaction) {
buffer->transaction->buffer = NULL; // 将这个事务的缓冲区清0
buffer->transaction = NULL; // 这个缓冲区指向的事务也置null
}
if (buffer->async_transaction && buffer->target_node) { // 如果这个缓冲区用于异步处理,并且他的实体对象还存在
BUG_ON(!buffer->target_node->has_async_transaction);
if (list_empty(&buffer->target_node->async_todo)) // 实体对象的异步事务队列是否为空
buffer->target_node->has_async_transaction = 0; // 空的话置0
else // 如果实体对象还有异步事务
// 把异步事务给当前线程,这个当前线程应该是server
list_move_tail(buffer->target_node->async_todo.next, &thread->todo);
}
binder_transaction_buffer_release(proc, buffer, NULL); // buffer里面有binder对象,减少他们的引用计数
// 释放这个buffer缓冲区,处理释放物理页之外,主要是把缓冲区前后合并之类的。这个buffer是内核的进程共享的映射关系
binder_free_buf(proc, buffer);
break;
}
```
由于这个有2个需要执行的命令,我们先看第一个。这个命令从命令也可以看出,是释放缓冲区的命令。首先获取用户缓冲区的地址,保存在data_ptr中。我们知道进程中分配的缓冲区都会被保存在一棵缓冲区的红黑树上,下面就通过binder_buffer_lookup这个方法来查找是否有这个缓冲区:
```c
// user_ptr是指向binder_buffer->data的用户空间地址,通过用户空间的地址转为内核缓冲区对应的binder_buffer
static struct binder_buffer *binder_buffer_lookup(
struct binder_proc *proc, void __user *user_ptr)
{
struct rb_node *n = proc->allocated_buffers.rb_node; // 获取已分配缓冲区红黑树
struct binder_buffer *buffer;
struct binder_buffer *kern_ptr;
// user_ptr是binder_buffer的data字段,offsetof(struct binder_buffer, data)表示指向了binder_buffer开始位置,减去 user_buffer_offset偏移值,就是内核空间binder_buffer的地址
kern_ptr = user_ptr - proc->user_buffer_offset
- offsetof(struct binder_buffer, data);
while (n) { // 遍历已经分配的缓冲区红黑树,寻找是否有kern_ptr这个节点,如果找到说明还在使用中,可以返回给上层,否则说明这个缓冲区已经不用了
buffer = rb_entry(n, struct binder_buffer, rb_node); // 获取已分配缓冲区红黑树节点
BUG_ON(buffer->free); // 如果是空闲的报错(这里是已分配嘛)
if (kern_ptr < buffer)
n = n->rb_left;
else if (kern_ptr > buffer)
n = n->rb_right;
else // 走到这里说明是 kern_ptr == buffer,即找到了。
return buffer;
}
return NULL;
}
```
首先通过proc->allocated_buffers.rb_node来获得分配的缓冲区红黑树根节点。由于这个传入的参数是进程缓冲区在内核的地址,由于整个binder流程确实来来回回的比较绕,有点同学可能已经记不清这个参数是什么时候在内核开辟的缓冲区,这里简单梳理下流程,当客户端请求注册的时候,binder驱动会在目标进程上,即service manager进程上开辟了一个缓冲区,这段代码是在binder驱动的binder_transaction方法中的:
```c
static void binder_transaction(struct binder_proc *proc, struct binder_thread *thread,
struct binder_transaction_data *tr, int reply)
{
struct binder_transaction *t;
...............
t->buffer = binder_alloc_buf(target_proc, tr->data_size,
tr->offsets_size, !reply && (t->flags & TF_ONE_WAY));
................
}
```
这里简单的贴了下代码,当初开辟缓冲区是在binder_transaction结构体的buffer上。这时候service manager可能正阻塞在binder驱动中等待任务,当binder驱动把上面这个事务项发给service manager的todo队列后,执行了binder驱动中的binder_thread_read方法:
```c
static int binder_thread_read(struct binder_proc *proc, struct binder_thread *thread,
void __user *buffer, int size, signed long *consumed, int non_block)
{
void __user *ptr = buffer + *consumed;
.................
struct binder_transaction_data tr;
...................
tr.data.ptr.buffer = (void *)t->buffer->data + proc->user_buffer_offset;
....................
if (copy_to_user(ptr, &tr, sizeof(tr)))
....................
}
```
这里可以看到从之前保存开辟缓冲区的结构体中取出缓冲区,即t->buffer->data,由于这个缓冲区是开辟的内核进程空间的,所以他的地址是内核的,后面加上proc->user_buffer_offset这个用户空间的差值,就能转换为用户进程的地址空间了,这个差值在前面讲内存映射的时候有说过,是在一个binder进程初始化的时候做内存映射就初始化的,这样是的用户进程和内核进程的共享内存地址是一个固定的差值,方面相互的转换。现在这个缓冲区地址就是用户空间的地址了,注意这个地址赋值给了binder_transaction_data这个结构体,我们先记住这个结构体,下面到用户空间后取这个值的时候再具体看这个结构体。最后通过copy_to_user方法就把这个结构体复制到用户空间了。下面流程走到service manager的binder_parse方法:
```c
int binder_parse(struct binder_state *bs, struct binder_io *bio,
uint32_t *ptr, uint32_t size, binder_handler func)
{
....................
struct binder_txn *txn = (void *) ptr;
.....................
binder_send_reply(bs, &reply, txn->data, res);
....................
}
```
到了这个方法,ptr就是用户空间的缓冲区,我们可以看到这个把ptr转为了binder_txn结构体,这个我们之前也说过了,他对应的是binder_transaction_data结构体,我们对比下2个结构体:
```c
struct binder_txn
{
void *target;
void *cookie;
uint32_t code;
uint32_t flags;
uint32_t sender_pid;
uint32_t sender_euid;
uint32_t data_size;
uint32_t offs_size;
void *data;
void *offs;
};
struct binder_transaction_data {
union {
size_t handle;
void *ptr;weakref_impl
} target;
void *cookie;
unsigned int code;
unsigned int flags;
pid_t sender_pid;
uid_t sender_euid;
size_t data_size;
size_t offsets_size;
union {
struct {
const void *buffer;
const void *offsets;
} ptr;
uint8_t buf[8];
} data;
};
```
对比两者,可以看到实际他们结构是一样的,只不过一个是联合体,所以多了些重叠的数据。到了这里txn->data其实就是结构体binder_transaction_data->ptr->buffer,也就是用户进程缓冲区,这样我们在回到前面讲的释放缓冲区方法中:
```c
static struct binder_buffer *binder_buffer_lookup(
struct binder_proc *proc, void __user *user_ptr)
{
struct rb_node *n = proc->allocated_buffers.rb_node; // 获取已分配缓冲区红黑树
struct binder_buffer *buffer;
struct binder_buffer *kern_ptr;
kern_ptr = user_ptr - proc->user_buffer_offset
- offsetof(struct binder_buffer, data); // user_ptr是binder_buffer的data字段,user_ptr-offsetof(struct binder_buffer, data)表示指向了binder_buffer开始位置,减去user_buffer_offset偏移值,就是内核空间binder_buffer的地址
while (n) { // 遍历已经分配的缓冲区红黑树,寻找是否有kern_ptr这个节点,如果找到说明还在使用中,可以返回给上层,否则说明这个缓冲区已经不用了
buffer = rb_entry(n, struct binder_buffer, rb_node); // 获取已分配缓冲区红黑树节点
BUG_ON(buffer->free); // 如果是空闲的报错(这里是已分配嘛)
if (kern_ptr < buffer)
n = n->rb_left;
else if (kern_ptr > buffer)
n = n->rb_right;
else // 走到这里说明是 kern_ptr == buffer,即找到了。
return buffer;
}
return NULL;
}
```
这里传入的参数user_ptr就是用户空间的地址,所以下面通过减去一个proc->user_buffer_offset值,再把他转化为内核地址值,然后再红黑树上寻找是否有这个值的节点,有的话就返回这个节点。好了,这个方法就说到这里。
如果获取了这个缓冲区后,经过一些处理后,最后就会调用binder_free_buf(proc, buffer)方法来释放这个缓冲区了。
```c
// Binder发送BR_TRANSATION或者BR_REPLY给进程后,进程处理完后,会发送BC_FREE_BUFFER给binder,通知可以释放内核缓冲区了,方法如下
static void binder_free_buf(
struct binder_proc *proc, struct binder_buffer *buffer) // buffer是要释放的缓冲区
{
size_t size, buffer_size;
buffer_size = binder_buffer_size(proc, buffer); // 计算要释放的缓冲区大小
size = ALIGN(buffer->data_size, sizeof(void *)) +
ALIGN(buffer->offsets_size, sizeof(void *)); // 计算缓冲区数据和偏移数组大小之和
.................................
if (buffer->async_transaction) { // 如果是一个异步事务,回加之前减去的大小
proc->free_async_space += size + sizeof(struct binder_buffer);
if (binder_debug_mask & BINDER_DEBUG_BUFFER_ALLOC_ASYNC)
printk(KERN_INFO "binder: %d: binder_free_buf size %zd "
"async free %zd\n", proc->pid, size,
proc->free_async_space);
}
binder_update_page_range(proc, 0,
(void *)PAGE_ALIGN((uintptr_t)buffer->data),
(void *)(((uintptr_t)buffer->data + buffer_size) & PAGE_MASK),
NULL); // 释放该缓冲区结构对应的数据(data字段)占用的物理页
rb_erase(&buffer->rb_node, &proc->allocated_buffers); // 从该进程已分配物理页缓冲区红黑树中删除
buffer->free = 1; // 设置改缓冲区为可用
if (!list_is_last(&buffer->entry, &proc->buffers)) { // 如果不是所有缓冲区链表中最后一个
struct binder_buffer *next = list_entry(buffer->entry.next,
struct binder_buffer, entry); // 获取当前缓冲区在链表上的下一个
if (next->free) { // 如果下一个也是空闲的,我们可以把2个合并。
rb_erase(&next->rb_node, &proc->free_buffers); // 把下一个节点从空闲缓冲区红黑树中删除
binder_delete_free_buffer(proc, next); // 在从缓冲区链表中删除next缓冲区结构体,如果结构体占用了物理页没有其他人用,释放物理页
}
}
if (proc->buffers.next != &buffer->entry) { // 如果不是所有缓冲区链表中第一个
struct binder_buffer *prev = list_entry(buffer->entry.prev,
struct binder_buffer, entry); // 取出前一个缓冲区
if (prev->free) { // 如果是空闲的
// 删除现在这个buffer结构体在缓冲区链表中的结点,如果结构体占用了物理页没有其他人用,释放物理页。另外这个方法里面会删除当前节点,然后把删除节点的前后连起来,所以pre现在和后面是连起来的,所以下面buffer=pre,等于是合并了节点
binder_delete_free_buffer(proc, buffer);
rb_erase(&prev->rb_node, &proc->free_buffers); // 从空闲红黑树上删除该节点
buffer = prev; // buffer切到前一个,即合并2个缓冲区
}
}
binder_insert_free_buffer(proc, buffer); // 把该空闲缓冲区加入空闲缓冲区红黑树
}
```
这个方法虽然代码处理的细节考虑比较多,但是整体逻辑比较简单,我们就说下整体的逻辑,首先计算下要释放的缓冲区大小,然后调用binder_update_page_range这个方法来释放缓冲区,之前在分配缓冲区的时候也是执行的这个方法,只不过第二个参数如果是1就是分配缓冲区,0就是释放缓冲区,这里就不多说了。释放后还会根据这个缓冲区前面是否相连的地址都是空闲的,如果有相连空闲的就合并他们,然后更新红黑树上缓冲区的数据。基本缓冲区释放的整体流程就是这样了,这部分就说到这。
## 给客户端发消息
我们记得之前service manager请求的时候除了这个是否缓冲区的命令外还有个BC_REPLY命令:
```c
case BC_REPLY: {
struct binder_transaction_data tr;
if (copy_from_user(&tr, ptr, sizeof(tr)))
return -EFAULT;
ptr += sizeof(tr);
binder_transaction(proc, thread, &tr, cmd == BC_REPLY);
break;
}
```
这个是给客户端发的回复,调用方法又回到binder_transaction,这个之前也是看过好几次了,只不过这次最后1个参数是1,我们看下这个的流程:
```c
static void
binder_transaction(struct binder_proc *proc, struct binder_thread *thread,
struct binder_transaction_data *tr, int reply)
{
................
f (reply) { // reply==1,是BC_REPLY命令
in_reply_to = thread->transaction_stack; // 这里thread是server的线程,获取事务栈顶
if (in_reply_to == NULL) {
binder_user_error("binder: %d:%d got reply transaction "
"with no transaction stack\n",
proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
goto err_empty_call_stack;
}
binder_set_nice(in_reply_to->saved_priority); // 恢复client线程的优先级
// 执行现场是否是本线程?
// 因为client提交请求后,轮到server线程执行,执行后会把执行的事务压入自己栈中
// 完成后会走到这里,这时候从栈顶取出的肯定要是本线程一样才行
if (in_reply_to->to_thread != thread) {
binder_user_error("binder: %d:%d got reply transaction "
"with bad transaction stack,"
" transaction %d has target %d:%d\n",
proc->pid, thread->pid, in_reply_to->debug_id,
in_reply_to->to_proc ?
in_reply_to->to_proc->pid : 0,
in_reply_to->to_thread ?
in_reply_to->to_thread->pid : 0);
return_error = BR_FAILED_REPLY;
in_reply_to = NULL;
goto err_bad_call_stack;
}
thread->transaction_stack = in_reply_to->to_parent; // 把栈顶变成前一个事务
target_thread = in_reply_to->from; // 获取client线程
if (target_thread == NULL) {
return_error = BR_DEAD_REPLY;
goto err_dead_binder;
}
if (target_thread->transaction_stack != in_reply_to) { // client线程的事务栈顶应该和server现在处理完的事务一样
binder_user_error("binder: %d:%d got reply transaction "
"with bad target transaction stack %d, "
"expected %d\n",
proc->pid, thread->pid,
target_thread->transaction_stack ?
target_thread->transaction_stack->debug_id : 0,
in_reply_to->debug_id);
return_error = BR_FAILED_REPLY;
in_reply_to = NULL;
target_thread = NULL;
goto err_dead_binder;
}
target_proc = target_thread->proc; // 这里应该是获取client进程
} else {
.......................
}
}
```
我们先看这一段,这里先从service manager的事务堆栈中取出栈顶事务,还记得吗,这个事务就是之前service manager在读取事务的时候压入自己栈顶的。现在把他弹出栈顶,并且通过他取得当初请求这个事务的线程和进程,保存在target_thread和target_proc中。我们接着往下看:
```c
.................
if (reply) {
BUG_ON(t->buffer->async_transaction != 0);
binder_pop_transaction(target_thread, in_reply_to);
} else if (!(t->flags & TF_ONE_WAY)) {
..............
} else {
...............
}
..................
t->buffer = binder_alloc_buf(target_proc, tr->data_size,
tr->offsets_size, !reply && (t->flags & TF_ONE_WAY));
....................
t->work.type = BINDER_WORK_TRANSACTION;
list_add_tail(&t->work.entry, target_list);
tcomplete->type = BINDER_WORK_TRANSACTION_COMPLETE;
list_add_tail(&tcomplete->entry, &thread->todo);
if (target_wait)
wake_up_interruptible(target_wait);
..................
```
这个事务除了service manager自己在读取的时候压入了栈中,在客户端请求的时候,客户端也把他压入自己的栈中,所以这里通过binder_pop_transaction方法从客户端线程堆栈中移除他,看下方法:
```c
static void
binder_pop_transaction(
struct binder_thread *target_thread, struct binder_transaction *t) // 从client线程target_thread中去掉in_reply_to工作项
{
if (target_thread) {
BUG_ON(target_thread->transaction_stack != t); // 只有在栈顶的事务才能删除
BUG_ON(target_thread->transaction_stack->from != target_thread); // 是不是本线程创建的
target_thread->transaction_stack =
target_thread->transaction_stack->from_parent; // 把事务栈切到下一个
t->from = NULL; // 当前事务创建者清0
}
t->need_reply = 0; // 当前事务不需要回复
if (t->buffer)
t->buffer->transaction = NULL; // 当前事务缓冲区设置没有事务使用
kfree(t); // 释放结构体
binder_stats.obj_deleted[BINDER_STAT_TRANSACTION]++;
}
```
方法很简单,做了下校验后,从栈顶移除。我们回到前面方法。
## service manager任务完成
最后还会添加2个工作项,一个再次向客户端进程发送BINDER_WORK_TRANSACTION任务,另一个是发给自己的BINDER_WORK_TRANSACTION_COMPLETE,表示完成的任务,这个任务自己接下去就会处理。注意这里和BINDER_WORK_TRANSACTION相关的事务时,方法在客户端这边又开辟了内存,这说明注册到service manager的进程也是个binder,所以他和内核也有内存映射,这里开辟了内存到后面肯定也有是否内存的地方,我们到后面再说。这里我们先看下BINDER_WORK_TRANSACTION_COMPLETE这个事务:
```c
case BINDER_WORK_TRANSACTION_COMPLETE: { // binder驱动返回给用户的命令
cmd = BR_TRANSACTION_COMPLETE;
if (put_user(cmd, (uint32_t __user *)ptr)) // 把这个通知写回到用户缓冲区中
return -EFAULT;
ptr += sizeof(uint32_t);
binder_stat_br(proc, thread, cmd); // 数据的统计
if (binder_debug_mask & BINDER_DEBUG_TRANSACTION_COMPLETE)
printk(KERN_INFO "binder: %d:%d BR_TRANSACTION_COMPLETE\n",
proc->pid, thread->pid);
list_del(&w->entry); // 从线程工作项链表中删除这个工作项
kfree(w); // 释放这个工作项
binder_stats.obj_deleted[BINDER_STAT_TRANSACTION_COMPLETE]++;
} break;
```
这个方法就是把一个BR_TRANSACTION_COMPLETE返回给service manager,然后把这个事务项删除掉。我们到service manager那边看一眼这个命令怎么处理的:
```c
int binder_parse(struct binder_state *bs, struct binder_io *bio,
uint32_t *ptr, uint32_t size, binder_handler func) // ptr是binder驱动返回的缓冲区
{
...............
case BR_TRANSACTION_COMPLETE:
break;
..............
}
```
## 客户端处理
这个命令什么时候都没做,好吧。至此,service manager这边就处理完了,他会接着阻塞在binder驱动那里等待着新的任务。我们在回去看下发送给客户端的任务:
```c
static int binder_thread_read(struct binder_proc *proc, struct binder_thread *thread,
void __user *buffer, int size, signed long *consumed, int non_block)
{
...............
case BINDER_WORK_TRANSACTION: {
t = container_of(w, struct binder_transaction, work); // t指向一个binder_transaction
} break;
..........
if (t->buffer->target_node) {
} else { // 没有实体对象情况,比如server向client回复时候
tr.target.ptr = NULL;
tr.cookie = NULL;
cmd = BR_REPLY;
}
tr.code = t->code; // 赋值命令
tr.flags = t->flags; // 赋值是否允许包含文件描述符
tr.sender_euid = t->sender_euid;
if (t->from) { // 如果有client发起事务的线程
struct task_struct *sender = t->from->proc->tsk; // 获取原进程的进程任务块
tr.sender_pid = task_tgid_nr_ns(sender, current->nsproxy->pid_ns); // 获取线程组ID
} else {
tr.sender_pid = 0;
}
tr.data_size = t->buffer->data_size; // 赋值缓冲区大小
tr.offsets_size = t->buffer->offsets_size; // 赋值缓冲区偏移数组大小
tr.data.ptr.buffer = (void *)t->buffer->data + proc->user_buffer_offset; // 保存缓冲区中的数据
tr.data.ptr.offsets = tr.data.ptr.buffer + ALIGN(t->buffer->data_size, sizeof(void *)); // 保存偏移数组
if (put_user(cmd, (uint32_t __user *)ptr)) // 把命令复制到用户空间的缓冲区
return -EFAULT;
ptr += sizeof(uint32_t);
if (copy_to_user(ptr, &tr, sizeof(tr))) // 把数据复制到用户空间的缓冲区
return -EFAULT;
ptr += sizeof(tr);
................
list_del(&t->work.entry); // 删除这个工作项
t->buffer->allow_user_free = 1; // 允许用户释放该缓冲区,这个buffer应该是client这边的内核缓冲区
.................
}
```
这里我们看到客户端取出之前service manager发过来的数据封装成binder_transaction_data结构体,然后命令cmd的值是BR_REPLY,把这些数据复制到用户空间后,删除这个工作项,这样程序会一层层返回到用户进程中,最终会返回到waitForResponse方法中:
```c
status_t IPCThreadState::waitForResponse(Parcel *reply, status_t *acquireResult) // 向binder驱动发送命令,等待回复的结果
{
............
cmd = mIn.readInt32();
............
case BR_REPLY: // 到这里client就收到了server发过来的回复了,剩下的主要任务就是根据返回数据处理
{
binder_transaction_data tr;
err = mIn.read(&tr, sizeof(tr)); // 获取server回复给client的数据
LOG_ASSERT(err == NO_ERROR, "Not enough command data for brREPLY");
if (err != NO_ERROR) goto finish;
if (reply) { // 如果Parcel非空
if ((tr.flags & TF_STATUS_CODE) == 0) { // 0表示请求被处理成功,把返回的缓冲区保存在parcel中
reply->ipcSetDataReference(
reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast<const size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof(size_t),
freeBuffer, this); // 析构reply时会调用freeBuffer这个方法,该方法中会调用BC_FREE_BUFFER来释放缓冲区
} else { // 处理失败了,直接是否缓冲区
err = *static_cast<const status_t*>(tr.data.ptr.buffer);
freeBuffer(NULL,
reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast<const size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof(size_t), this);
}
} else { // 如果Parcel为空,直接调用freeBuffer释放内核中的缓冲区
freeBuffer(NULL,
reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast<const size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof(size_t), this);
continue;
}
}
...............
}
```
这里进入BR_REPLY的分支,之前service manager传过来的flags为0,所以接着会调用reply->ipcSetDataReference方法,这里要注意的是这个方法的倒数第二个参数freeBuffer,我们看下他的实现:
```c
void IPCThreadState::freeBuffer(Parcel* parcel, const uint8_t* data, size_t dataSize,
const size_t* objects, size_t objectsSize,
void* cookie)
{
//LOGI("Freeing parcel %p", &parcel);
IF_LOG_COMMANDS() {
alog << "Writing BC_FREE_BUFFER for " << data << endl;
}
LOG_ASSERT(data != NULL, "Called with NULL data");
if (parcel != NULL) parcel->closeFileDescriptors();
IPCThreadState* state = self();
state->mOut.writeInt32(BC_FREE_BUFFER);
state->mOut.writeInt32((int32_t)data);
}
};
```
可以看到他往写缓冲区中写入了BC_FREE_BUFFER的指令,前面我们介绍过,这个是释放缓冲区的,这个方法被传入的ipcSetDataReference方法中,我们在看看ipcSetDataReference方法的实现:
```c
void Parcel::ipcSetDataReference(const uint8_t* data, size_t dataSize,
const size_t* objects, size_t objectsCount, release_func relFunc, void* relCookie)
{
freeDataNoInit(); // 先释放mData和mObjects
mError = NO_ERROR;
mData = const_cast<uint8_t*>(data); // 设置数据区
mDataSize = mDataCapacity = dataSize; // 设置数据区大小
//LOGI("setDataReference Setting data size of %p to %lu (pid=%d)\n", this, mDataSize, getpid());
mDataPos = 0; // 数据开始位置为0
LOGV("setDataReference Setting data pos of %p to %d\n", this, mDataPos);
mObjects = const_cast<size_t*>(objects); // 设置偏移数组
mObjectsSize = mObjectsCapacity = objectsCount; // 设置偏移数组大小
mNextObjectHint = 0;
mOwner = relFunc; // 析构函数中会调用这个方法,这个方法
mOwnerCookie = relCookie;
scanForFds();
}
```
这个是Parcel的方法,主要是根据binder那边传过来的缓冲区数据,保存在本地。其中前面介绍的那个释放缓冲区的方法被赋值给了mOwner变量,这是个方法指针,我们在Parcel的析构方法里面可以看到他被调用了:
```c
void Parcel::freeDataNoInit()
{
if (mOwner) {
//LOGI("Freeing data ref of %p (pid=%d)\n", this, getpid());
mOwner(this, mData, mDataSize, mObjects, mObjectsSize, mOwnerCookie);
} else {
releaseObjects();
if (mData) free(mData);
if (mObjects) free(mObjects);
}
}
```
可以看到当Parcel被析构时,自然缓冲区也不用了,会触发写入BC_FREE_BUFFER指令的方法。至此整个添加一个服务的流程走完了。整个的过程可以说是非常的漫长,进程之间也多次进行交互。注册完后一般服务和service manager一样会有binder线程阻塞在binder驱动中,一旦有新任务到来,就会唤醒线程来执行任务。
addService方法到这篇就都讲完了,既然注册了一个服务,自然是有获取服务的需求的,不过其实我们获取service manager已经是一个获取服务的过程了,所以之前也讲过了,但是由于service manager比较特殊,可以看做一个根服务,记不记得,他的地址被设置为0,和一般其他服务不一样。所以下篇我们来分析下service manager的getService方法,看看如何来获取一个普通的服务的。好了,最后还是把这篇文章的时序图画一下,梳理一下流程。
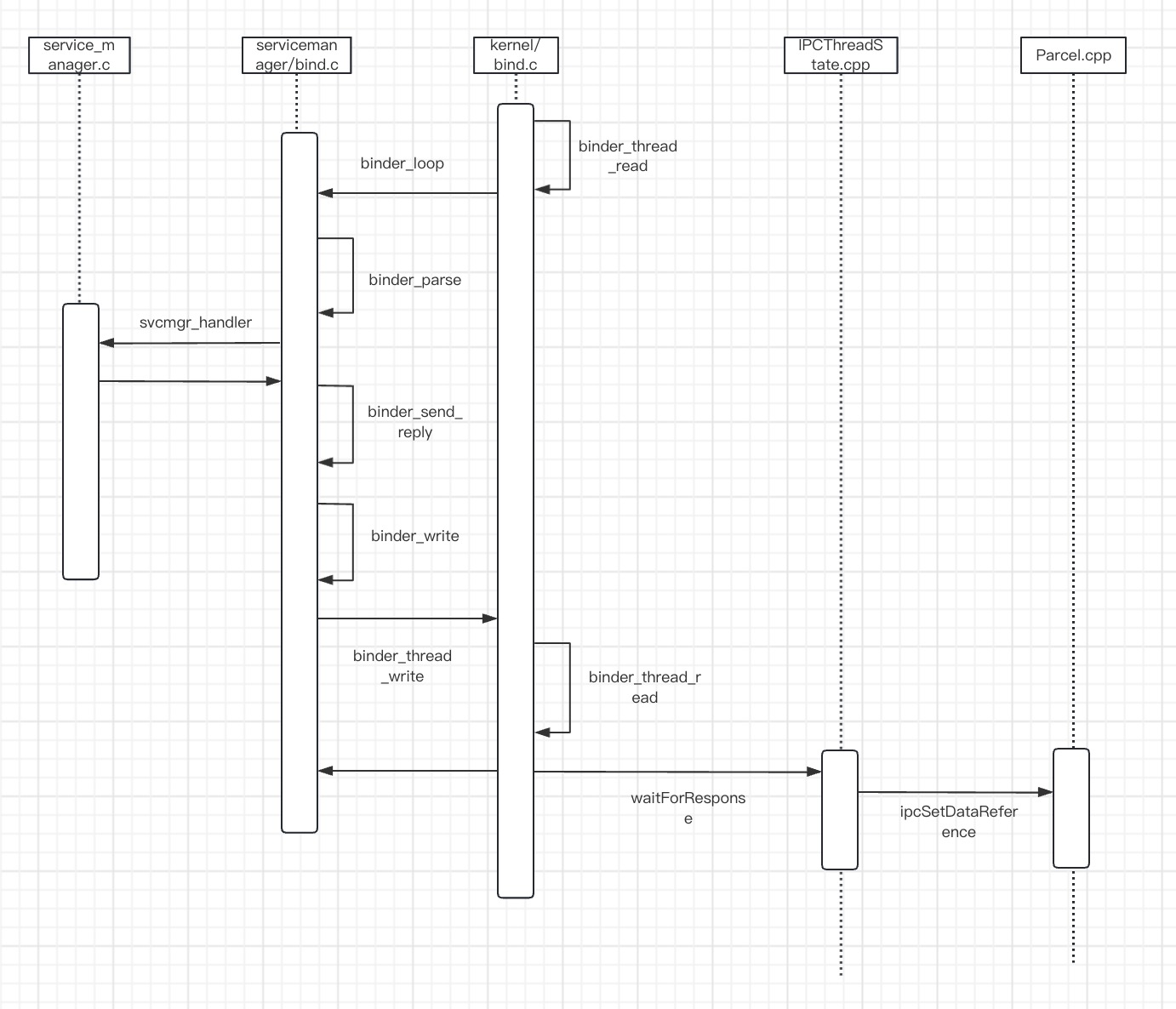

Android进程间通信Binder(五)