
从这篇文章开始,准备讲一讲android启动方面的流程。我们知道android是基于linux操作系统来开放的,所以它开始的启动流程和linux也是一样的,但是在加载完内核后,就开始android自己的一套东西。对于linux来说,他启动的时候,首先会有引导流程,引导流程和具体的硬件体系有关,比如x86体系,一般会在内存地址ox7c00处加载引导程序,通过引导程序在加载内核,内核加载完后就开始了就开始衍生出了一系列的系统进程和用户进程了。Android也是类似的,由于android主要运行arm的体系结构上,所以他是通过bootloader来引导,之后加载完内核后,就到从init进程开始了。所以我们这篇文章主要是从init进程开始说起,他是android内核加载完成后的第一个用户空间进程,所以可以看成是代表android系统自己的一个东西,之后会fork出zygote进程,这个相信大家也都听说过的,所以后续的进程都是从这个进程fork出来的,所以它可以看做是后面进程的父进程。其实SystemServer进程就是他fork出的一个重要进程,在SystemServer进程中初始化很多系统重要的组件,比如我们熟知的AMS,WMS等就是在SystemServer中初始化,当前最后androd的桌面程序Launcher也是从SystemServer启动的。所以我们从这篇文章准备把从init进程开始,经过zygote,最后到SystemServer进程的流程分析下,看看他们到底做了些什么,也可以知道android系统的启动过程。好了,下面我们就先从init进程开始。
# init进程入口
虽然我们从init进程开始说,他也是系统用户空间中的第一个进程,进程号pid是1,但是他也是被别人fork出来的,所以pid是1而不是0,而pid为0的也就是内核空间的进程了。这里稍微提一下,所谓内核空间和用户空间,一般都是指虚拟空间,自从计算机有了保护模式和分页后,所有程序的内容地址都是虚拟的,给出一个虚拟地址后,通过系统的分页来计算出最终的物理地址,这样每个进程就会感觉自己所拥有的内存空间非常大,不会因为实际内存已经被其他进程占用了而得不到执行(当然实际系统会通过把其他进程交换出内存,来达到加载进程的目的),所以空间只是逻辑上的,不是物理上的,这点要知道。另外由于内核程序赋值着整个系统个各项工作,所以不能虽然对他做修改,只有有权限才能执行内核空间的东西,鉴于此linux系统把内核单独划为一个空间,这个空间是准备存放内核的代码和数据的,所以他叫做内核空间,剩余的就叫做用户空间了。
我们知道了内核空间和用户空间的概念后,前面说了init进程是第一个用户空间进程,他是内核空间进程fork出来的,但是我们说init是一个系统进程,这个系统不是指内核,而在android里的系统概念,这个也不要和linux内核搞混了。内核和用户进程是从linux操作系统体系这个角度来说的,而我们在讲android系统进程的时候是从android这个角度来说的,两者不是一个概念,也就是说虽然init进程运行在操作系统的用户地址空间,但是他是android的系统进程,经过解释后这个应该不难理解吧。
好了,我们继续说init进程。init之前的我们就先不说了,主要从init启动后开始说,init文件所在位置为system/core/init/init.cpp,我们来看他的main方法:
```cpp
int main(int argc, char** argv) {
.............
// 把BuiltinFunctionMap类初始化,赋值给action的function_map_
const BuiltinFunctionMap function_map;
Action::set_function_map(&function_map);
// 这里开始解析init.rc
Parser& parser = Parser::GetInstance();
// 添加三个类型的命令,service,action,import
parser.AddSectionParser("service",std::make_unique<ServiceParser>());
parser.AddSectionParser("on", std::make_unique<ActionParser>());
parser.AddSectionParser("import", std::make_unique<ImportParser>());
// bootscript表示自定义init.rc
std::string bootscript = GetProperty("ro.boot.init_rc", "");
// 看看配置文件中有没有给出init.文件,解析出init.rc中的命令字符,结果最终会保存在services_集合中
if (bootscript.empty()) {
parser.ParseConfig("/init.rc");
parser.set_is_system_etc_init_loaded(
parser.ParseConfig("/system/etc/init"));
parser.set_is_vendor_etc_init_loaded(
parser.ParseConfig("/vendor/etc/init"));
parser.set_is_odm_etc_init_loaded(parser.ParseConfig("/odm/etc/init"));
} else {
parser.ParseConfig(bootscript);
parser.set_is_system_etc_init_loaded(true);
parser.set_is_vendor_etc_init_loaded(true);
parser.set_is_odm_etc_init_loaded(true);
}
...................
while (true) {
............
if (!(waiting_for_prop || ServiceManager::GetInstance().IsWaitingForExec())) {
// 这里开始执行rc文件解析的内容
am.ExecuteOneCommand();
}
............
}
}
```
这里方法里面做了不少事,很多和操作系统初始化有关的我们略过,这里主要给出和我们准备分析的系统启动主流程有关的部分。
首先我们看到BuiltinFunctionMap这个类,接着调用了Action中的set_function_map这个方法,把这个类的实例传了进去,我们看下set_function_map,这个方法:
```cpp
const KeywordMap<BuiltinFunction>* Action::function_map_ = nullptr;
static void set_function_map(const KeywordMap<BuiltinFunction>* function_map) {
function_map_ = function_map;
}
```
这个方法的参数接受一个指针,指向一个泛型是BuiltinFunction的类,传入的就是一个BuiltinFunction。这里我们简单看下涉及到的两个类,首先看下BuiltinFunction这个类:
```cpp
class BuiltinFunctionMap : public KeywordMap<BuiltinFunction> {
public:
// 构造函数
BuiltinFunctionMap() {
}
private:
Map& map() const override;
};
```
这个类继承了KeywordMap模板类,他有一个私有方法map,返回的类型也是Map,我们看下这个map里是什么:
```cpp
BuiltinFunctionMap::Map& BuiltinFunctionMap::map() const {
constexpr std::size_t kMax = std::numeric_limits<std::size_t>::max();
// clang-format off
static const Map builtin_functions = {
{"bootchart", {1, 1, do_bootchart}},
{"chmod", {2, 2, do_chmod}},
{"chown", {2, 3, do_chown}},
{"class_reset", {1, 1, do_class_reset}},
{"class_restart", {1, 1, do_class_restart}},
{"class_start", {1, 1, do_class_start}},
{"class_stop", {1, 1, do_class_stop}},
{"copy", {2, 2, do_copy}},
{"domainname", {1, 1, do_domainname}},
{"enable", {1, 1, do_enable}},
{"exec", {1, kMax, do_exec}},
{"exec_start", {1, 1, do_exec_start}},
{"export", {2, 2, do_export}},
{"hostname", {1, 1, do_hostname}},
{"ifup", {1, 1, do_ifup}},
{"init_user0", {0, 0, do_init_user0}},
{"insmod", {1, kMax, do_insmod}},
{"installkey", {1, 1, do_installkey}},
{"load_persist_props", {0, 0, do_load_persist_props}},
{"load_system_props", {0, 0, do_load_system_props}},
{"loglevel", {1, 1, do_loglevel}},
{"mkdir", {1, 4, do_mkdir}},
{"mount_all", {1, kMax, do_mount_all}},
{"mount", {3, kMax, do_mount}},
{"umount", {1, 1, do_umount}},
{"restart", {1, 1, do_restart}},
{"restorecon", {1, kMax, do_restorecon}},
{"restorecon_recursive", {1, kMax, do_restorecon_recursive}},
{"rm", {1, 1, do_rm}},
{"rmdir", {1, 1, do_rmdir}},
{"setprop", {2, 2, do_setprop}},
{"setrlimit", {3, 3, do_setrlimit}},
{"start", {1, 1, do_start}},
{"stop", {1, 1, do_stop}},
{"swapon_all", {1, 1, do_swapon_all}},
{"symlink", {2, 2, do_symlink}},
{"sysclktz", {1, 1, do_sysclktz}},
{"trigger", {1, 1, do_trigger}},
{"verity_load_state", {0, 0, do_verity_load_state}},
{"verity_update_state", {0, 0, do_verity_update_state}},
{"wait", {1, 2, do_wait}},
{"wait_for_prop", {2, 2, do_wait_for_prop}},
{"write", {2, 2, do_write}},
};
// clang-format on
return builtin_functions;
}
```
可以看到这里map是一个以string为key,一个三元组为value的map,这个有什么用呢,我们先记住这个数据结构,后面用到的时候再说,然后也简单看下KeywordMap这个模板类:
```cpp
template <typename Function>
class KeywordMap {
public:
using FunctionInfo = std::tuple<std::size_t, std::size_t, Function>;
using Map = const std::map<std::string, FunctionInfo>;
...........
const Function FindFunction(const std::string& keyword,
size_t num_args,
std::string* err) const {
...............
auto function_info_it = map().find(keyword);
................
auto function_info = function_info_it->second;
................
return std::get<Function>(function_info);
.............
}
}
```
这里我们也不用细看,直接看这几个关键点。首先前面BuiltinFunctionMap类中的Map是在这里定义的,他们的key是string,value是FunctionInfo,而FunctionInfo是一个tuple三元组。
之后我们看到这里还定义了一个方法FindFunction,从下面这个方法返回的结果可以看到,这个返回的结果是从map方法中通过指定的String获得的那个三元组,然后返回结果是这个三元组的最后一个。我们现在是不是有种模糊的感觉,后面会调用这个方法来获得这个三元组中的元素,我们又感觉就行了,还是卖个关子后面分析到的时候说。我们返回init.cpp的main方法,继续往下看。
之后会获取一个Parser实例,然后往这个Parser实例中添加三个SectionParser的子类,分别是ServiceParser,ActionParser和ImportParser,这3个子类是用来解析后面命令的,这里添加的方法是AddSectionParser:
```c++
std::map<std::string, std::unique_ptr<SectionParser>> section_parsers_;
void Parser::AddSectionParser(const std::string& name,
std::unique_ptr<SectionParser> parser) {
section_parsers_[name] = std::move(parser);
}
```
这里分别把service,on和import作为3个SectionParser子类的key,添加到map中,具体他们用法我们也在后面说,这里记住section_parsers_这个map保存了3个类就可以了。
之后要开始解析命令的文件了,在解析过程中会用到上面说的几个类。解析的文件中保存了后面要启动的一些进程命令。这些命令可以自己定制,如果自己定制的话会放在ro.boot.init_rc这个文件中,默认的话会使用system/core/rootdir/init.rc这个文件,我们现在分析就分析这个默认的,这个文件内容比较多,由于我们下面要启动的是zygote进程,所以就挑和zygote进程有关的命令我分析这个文件,其他也是类似的语法。
记得上面我们添加了3个SectionParser的子类到section_parsers_这个map吗,他们的key分别是service,on,import。我们先说这个import,这个就和我们开发中导入一个类是一个意思,被导入的文件中的内容可以再当前文件中使用,我们看下init.rc中这个import的一个例子:
```cpp
import /init.${ro.zygote}.rc
```
这里导入了一个init.xxx.rc文件,这个xxx是根据硬件类型不同来产生的,比如如果是32位的操作系统,这个文件名就会是init.zygote32.rc,这个文件可以在和zygote相同目录下找到:
```cpp
service zygote /system/bin/app_process -Xzygote /system/bin --zygote --start-system-server
class main
priority -20
user root
group root readproc
socket zygote stream 660 root system
onrestart write /sys/android_power/request_state wake
onrestart write /sys/power/state on
onrestart restart audioserver
onrestart restart cameraserver
onrestart restart media
onrestart restart netd
onrestart restart wificond
writepid /dev/cpuset/foreground/tasks
```
熟悉linux命令的同学可能会知道,service命令就是启动一个service,这里其实也是一样的。第一个service就是启动的命令,第二个/system/bin/app_process是执行文件的路径,后面的都是执行的参数。从第二行开始是可选的启动项,比如onrestart这个命令是只如果这个service重启的时候,需要启动的其他项。这些启动命令,下面我们就会看到他的解析过程。
这里特别提一下的是这个执行路径。我们看到/system/bin/app_process这个路径,这里分为两部分,/system/bin/这个会在系统启动后把可执行的二进制文件放在这里,这里的话这个文件就是app_process,而他是app_process这个模块的mk文件中配置的名字:
```c
LOCAL_PATH:= $(call my-dir)
app_process_common_shared_libs := \
libandroid_runtime \
libbinder \
libcutils \
libdl \
libhwbinder \
liblog \
libnativeloader \
libutils \
# This is a list of libraries that need to be included in order to avoid
# bad apps. This prevents a library from having a mismatch when resolving
# new/delete from an app shared library.
# See b/21032018 for more details.
app_process_common_shared_libs += \
libwilhelm \
app_process_common_static_libs := \
libsigchain \
app_process_src_files := \
app_main.cpp \
app_process_cflags := \
-Wall -Werror -Wunused -Wunreachable-code
app_process_ldflags_32 := \
-Wl,--version-script,art/sigchainlib/version-script32.txt -Wl,--export-dynamic
app_process_ldflags_64 := \
-Wl,--version-script,art/sigchainlib/version-script64.txt -Wl,--export-dynamic
include $(CLEAR_VARS)
LOCAL_SRC_FILES:= $(app_process_src_files)
LOCAL_LDFLAGS_32 := $(app_process_ldflags_32)
LOCAL_LDFLAGS_64 := $(app_process_ldflags_64)
LOCAL_SHARED_LIBRARIES := $(app_process_common_shared_libs)
LOCAL_WHOLE_STATIC_LIBRARIES := $(app_process_common_static_libs)
LOCAL_MODULE:= app_process
LOCAL_MULTILIB := both
LOCAL_MODULE_STEM_32 := app_process32
LOCAL_MODULE_STEM_64 := app_process64
LOCAL_CFLAGS += $(app_process_cflags)
# In SANITIZE_LITE mode, we create the sanitized binary in a separate location (but reuse
# the same module). Using the same module also works around an issue with make: binaries
# that depend on sanitized libraries will be relinked, even if they set LOCAL_SANITIZE := never.
#
# Also pull in the asanwrapper helper.
ifeq ($(SANITIZE_LITE),true)
LOCAL_MODULE_PATH := $(TARGET_OUT_EXECUTABLES)/asan
LOCAL_REQUIRED_MODULES := asanwrapper
endif
include $(BUILD_EXECUTABLE)
# Create a symlink from app_process to app_process32 or 64
# depending on the target configuration.
ifneq ($(SANITIZE_LITE),true)
include $(BUILD_SYSTEM)/executable_prefer_symlink.mk
endif
```
这个mk文件我们看到LOCAL_MODULE:= app_process,这个模块就是app_process。另外app_process_src_files := app_main.cpp我们可以看到,源文件是app_main.cpp,所以后面我们分析zygote源码的时候会到这个文件里面去看。
上面说了import和service两个命令,剩下还有个on命令,在上面的代码中on命令代表一个ActionParser的子类,表示一个具体执行的动作,我们可以把on命令看做是其他命令的一个入口,比如上面我们看到启动一个service的,最开始就是同on命令来触发的,经过一系列的寻找最终会找到service命令,比如我们看下面这个命令:
```cpp
on zygote-start && property:ro.crypto.state=unsupported
# A/B update verifier that marks a successful boot.
exec_start update_verifier_nonencrypted
start netd
start zygote
start zygote_secondary
```
这是个on命令,命令的名字是zygote-start,&&后面的是命令的属性值,下面exec_start,start这里表示调用某个方法的名字,比如start表示调用do_start方法,具体这个方法在什么地方,先别急我们后面会说,现在有个印象就好,后面zygote就是调用这个方法的参数。其实这么一说,大家可能就知道这会不会是启动zygote进程的命令啊,确实是的,具体怎么启动的我们下面一点点看源码分析。另外,init.rc中还会看到有这样的命令:
```cpp
trigger zygote-start
```
trigger也是触发一个方法,这个方法的作用就是调用on zygote-start这个命令,其实就和上面的一样了,这个也了解下。好,下面我们开始分析解析这些命令的源码。
# 解析init.c文件命令
我们回到init.cpp的main方法,前面我们讲到解析init.rc这个文件,具体的解析方法是Parser类的ParseConfig方法,我们看下这个方法:
```cpp
bool Parser::ParseConfig(const std::string& path) {
// 如果path是一个文件夹,调用ParseConfigDir加入容器后再解析
if (is_dir(path.c_str())) {
return ParseConfigDir(path);
}
return ParseConfigFile(path);
}
```
这个方法会判断path是文件夹还是文件,如果是文件夹,会调用ParseConfigDir方法继续解析,如果是文件则调用ParseConfigFile方法来解析。我们先看下解析文件夹的方法:
```cpp
// 遍历文件夹,把文件路径放入容器,排序后解析
bool Parser::ParseConfigDir(const std::string& path) {
LOG(INFO) << "Parsing directory " << path << "...";
// 指向文件夹
std::unique_ptr<DIR, int(*)(DIR*)> config_dir(opendir(path.c_str()), closedir);
if (!config_dir) { // 如果文件是空,return
PLOG(ERROR) << "Could not import directory '" << path << "'";
return false;
}
dirent* current_file;
std::vector<std::string> files;
// 遍历文件
while ((current_file = readdir(config_dir.get()))) {
// Ignore directories and only process regular files.
if (current_file->d_type == DT_REG) {
// 获得文件路径
std::string current_path =
android::base::StringPrintf("%s/%s", path.c_str(), current_file->d_name);
// 往容器尾部添加
files.emplace_back(current_path);
}
}
// Sort first so we load files in a consistent order (bug 31996208)
std::sort(files.begin(), files.end()); // 排序
for (const auto& file : files) {
if (!ParseConfigFile(file)) { // 解析
LOG(ERROR) << "could not import file '" << file << "'";
}
}
return true;
}
```
这个方法首先会获得这个文件夹的路径,然后遍历这个文件夹,如果是文件的话,会把这个文件的路径加入files容器。遍历完后会进行排序,最后会调用ParseConfigFile方法进行文件解析。这样的话,解析文件夹最后也会走解析文件的流程,那么两者就统一起来了,我们继续看解析文件的方法ParseConfigFile:
```cpp
bool Parser::ParseConfigFile(const std::string& path) {
LOG(INFO) << "Parsing file " << path << "...";
Timer t;
std::string data;
// 读取文件
if (!read_file(path, &data)) {
return false;
}
data.push_back('\n'); // TODO: fix parse_config.
ParseData(path, data); // 解析文件
for (const auto& sp : section_parsers_) {
sp.second->EndFile(path);
}
LOG(VERBOSE) << "(Parsing " << path << " took " << t << ".)";
return true;
}
```
这个方法首先把文件的内容读取到data变量中,然后再调用ParseData继续解析,我们继续看ParseData方法:
```cpp
void Parser::ParseData(const std::string& filename, const std::string& data) {
//TODO: Use a parser with const input and remove this copy
std::vector<char> data_copy(data.begin(), data.end()); // 字符串,即文件内容
data_copy.push_back('\0');
parse_state state;
state.filename = filename.c_str(); // 文件名
state.line = 0; // 函数
state.ptr = &data_copy[0]; // 第一个字符
state.nexttoken = 0;
SectionParser* section_parser = nullptr;
std::vector<std::string> args;
for (;;) {
switch (next_token(&state)) {
case T_EOF: // 结束符
if (section_parser) {
section_parser->EndSection();
}
return;
case T_NEWLINE: // 换行
state.line++;
if (args.empty()) {
break;
}
// init.cpp的main方法中,解析前添加过
// service,on,import三个SectionParser
// 所以count方法表示是否这个map中有这个key的元素
// 有的话,说明这里返回的是命令,不是参数
if (section_parsers_.count(args[0])) {
if (section_parser) { // 添加到service结合中
section_parser->EndSection();
}
// 取出service,on,import三个命令类型的一种
section_parser = section_parsers_[args[0]].get();
std::string ret_err;
// 解析带service命令的一行,最后创建一个service对象
if (!section_parser->ParseSection(args, &ret_err)) {
parse_error(&state, "%s\n", ret_err.c_str());
section_parser = nullptr;
}
} else if (section_parser) {
// 到这里说明返回的是参数,下面解析参数
std::string ret_err;
// 解析不带service命令一行,即解析参数
if (!section_parser->ParseLineSection(args, state.filename,
state.line, &ret_err)) {
parse_error(&state, "%s\n", ret_err.c_str());
}
}
args.clear();
break;
case T_TEXT: // 返回的是正常的一行字符串,放入string容器中
args.emplace_back(state.text);
break;
}
}
}
```
这个方法里有个变量parse_state,里面保存了传过来的命令数据,比如ptr指向数据中的一个字符。下面的处理会遍历所有的数据,根据数据返回的不同情况做不同处理。
下面遍历过程中,分为三种情况:
1. 第一种情况是结束符,如果是结束符的话,那说明已经解析完成了,接着会把解析好的数据保存在一个集合中,提供给后面执行命令的时候会用,执行的方法是SectionParser的EndSection,这个方法我们后面会讲。
2.第二种情况是换行符,这种情况的话,说明命令新起了一行,但是还没结束,所以把前一行处理一下一下,然后继续解析新的一行。值得注意的是,这种情况也有两种情形,一种是前一行是整个命令的第一行,那么这行的开头的命令肯定是import,service或者on中的一个,那么会创建之前说的SectionParser三个子类的其中一个,即ImportParser,ServiceParser或者ActionParser,然后调用他们的ParseSection方法来解析。否则如果开头的命令不是这三种,说明命令是从第二行开始的,那么会调用ParseLineSection来解析。不论怎么样,都会先处理完一行,在继续处理下一行,如果是第一行的解析,处理就是保存在一个对象中,对象目前就三种,service,action或者import。如果不是第一行,根据不同的命令做不同的解析处理,总体来说也是把数据保存下来,等待后面的使用。
3. 第三种情况,如果一行还没有全部读取就结束了,比如由于命令和参数之间都用空格作为分隔符,所以没读取一个单词的话,就会返回,这种情况会把读取的一段字符串保存在args这个容器中,等到第二种情况处理这个容器中保存的一行的数据。
总体来说就是以上三种情况,我们先看下next_token这个方法,这个方法是读取数据的时候返回的逻辑:
```cpp
// 计算每个字符,根据不同情况计算返回,计算的结果
int next_token(struct parse_state *state)
{
char *x = state->ptr;
char *s;
if (state->nexttoken) {
int t = state->nexttoken;
state->nexttoken = 0;
return t;
}
for (;;) {
switch (*x) {
case 0: // 结束符
state->ptr = x;
return T_EOF;
case '\n': // 换行
x++;
state->ptr = x; // 指针指向下一个字符,退出
return T_NEWLINE;
case ' ': // 空格
case '\t': // 制表符
case '\r':
x++; // 指向下一个字符,for循环继续判断
continue;
case '#': // 注释
while (*x && (*x != '\n')) x++;
// 经过上面while循环,说明要么空,要么换行
if (*x == '\n') { // 换行
state->ptr = x+1; // 指向下一个
return T_NEWLINE;
} else { // 空的话,就是结束符
state->ptr = x;
return T_EOF;
}
default:
goto text;
}
}
textdone:
state->ptr = x;
*s = 0;
return T_TEXT;
text: // 到这里说明是正常字符,先把字符记录在s中
state->text = s = x;
textresume:
for (;;) {
switch (*x) {
case 0: // 结束
goto textdone;
case ' ': // 空格
case '\t':
case '\r':
x++;
goto textdone;
case '\n': // 换行,说明可能这里有2行,第一行是命令,第二行是换行,所以返回后要把第一行读取出来
state->nexttoken = T_NEWLINE;
x++;
goto textdone;
case '"': // 命令行中的字符串
x++;
for (;;) {
switch (*x) {
case 0:
/* unterminated quoted thing */
state->ptr = x;
return T_EOF;
case '"': // 命令行中的字符串结束
x++;
goto textresume;
default:
*s++ = *x++;
}
}
break;
case '\\': // 转义符
x++;
switch (*x) {
case 0:
goto textdone;
case 'n':
*s++ = '\n';
break;
case 'r':
*s++ = '\r';
break;
case 't':
*s++ = '\t';
break;
case '\\':
*s++ = '\\';
break;
case '\r':
/* \ <cr> <lf> -> line continuation */
if (x[1] != '\n') {
x++;
continue;
}
case '\n':
/* \ <lf> -> line continuation */
state->line++; // 转义符也有换行,行数+1
x++;
/* eat any extra whitespace */
while((*x == ' ') || (*x == '\t')) x++;
continue;
default:
/* unknown escape -- just copy */
*s++ = *x++;
}
continue;
default:
*s++ = *x++;
}
}
return T_EOF;
}
```
这个方法看上去不算很短,但是整体就是我们上面说的三种情况。
首先如果是一个正常数据的话,开头的命令肯定是一个正常的字符串,所以这里开始有个for循环,如果开始就遇到了比如结束符,换行,空格等特殊符号,要么就返回,要么就继续往后遍历。
之后如果遇到了一个正常的字符的话,会继续往前走,知道遇到结束符,空格等符号,说明一段结束了。如果遇到换行符,说明一行结束了。这里还有些异常的处理,比如有上引号开头但是没有上引号结束就遇到结束符了,就会返回T_EOF。当然还有转义符的处理,这里也不一一细说了,感兴趣的同学可以看下代码,不是很难。
说完了next_token方法后,我们看下上面说的解析返回后的三种情况下涉及到的代码,第一种和第三种比较简单,我们最后说,先看下第二种情况。
第二种情况上面我们分析的时候说了,也会分为两种情况,第一种情况是解析命令的第一行,解析的方法是ParseSection。非第一行解析的方法是ParseLineSection。
这里是怎么判断是否是第一行的呢?我们知道如果是第一行,命令开头肯定就是import,on,service这三个之一,那么字符串中肯定有这3个字符,根据上面我们说的第三种情况,一行中主要有一段字符串被解析出来了就返回后保存在args容器中,所以我们只要取出args的开头字符就可以知道是否是第一行了。
这里需要回忆以上我们开头分析代码的时候,还记得提到的section_parsers_这个map吗?我们把三个SectionParser的子类添加到了这个map,他们的key分别是service,on,import,所以这里只需要从这个map中取出对应的子类SectionParser就可以了,下面会通过这个子类进行解析。
由于这里的解析分别有import,service和action三种命令的解析,我们主要看下service和action的,这两种是我们主要遇到的,import导入相对比较容易这里就不多说了。
我们先看ServiceParse的ParseSection方法,这是解析一个service命令第一行的方法:
```cpp
// 解析带service命令的一行,最后创建一个service对象
bool ServiceParser::ParseSection(const std::vector<std::string>& args,
std::string* err) {
// service命令肯定要大于3个元素,比如service zygote /system/bin/app_process -xxxxx这样
if (args.size() < 3) {
*err = "services must have a name and a program";
return false;
}
const std::string& name = args[1]; // 命令名字
if (!IsValidName(name)) { // 校验名字是否合法
*err = StringPrintf("invalid service name '%s'", name.c_str());
return false;
}
// service文件名到后面的参数
std::vector<std::string> str_args(args.begin() + 2, args.end());
// new一个service对象
service_ = std::make_unique<Service>(name, str_args);
return true;
}
```
首先会判断一下service命令参数不能少于3个,一般除了service命令本身,起码还有service的名字和文件路径,所以不能少于3个。之后会对service命令规则做一下校验,最后把从文件路径开始的字符串保存在service_这个变量中,这样就处理好了,看了service这个方法主要就是保存下从文件路径开始的参数。
看完了service的解析,我们在看下on命令的第一行解析,即ActionParser的ParseSection方法:
```cpp
bool ActionParser::ParseSection(const std::vector<std::string>& args,
std::string* err) {
// 保存on命令参数
std::vector<std::string> triggers(args.begin() + 1, args.end());
if (triggers.size() < 1) {
*err = "actions must have a trigger";
return false;
}
// 创建一个Action
auto action = std::make_unique<Action>(false);
// 初始化这个action,即传入参数
if (!action->InitTriggers(triggers, err)) {
return false;
}
// action保存到action_集合
action_ = std::move(action);
return true;
}
```
首先把on命令的参数保存在triggers容器中,之后会调用InitTriggers方法对这些参数进行初始化,初始化后会保存在action对象中,最终还会保存在action_容器中。我们看下初始化方法InitTriggers:
```cpp
bool Action::InitTriggers(const std::vector<std::string>& args, std::string* err) {
const static std::string prop_str("property:");
// 遍历这个args,即action(on命令)的参数
for (std::size_t i = 0; i < args.size(); ++i) {
if (args[i].empty()) {
*err = "empty trigger is not valid";
return false;
}
if (i % 2) {
if (args[i] != "&&") {
*err = "&& is the only symbol allowed to concatenate actions";
return false;
} else {
continue;
}
}
// 如果是on property<属性>=<值>这种格式的on命令
if (!args[i].compare(0, prop_str.length(), prop_str)) {
if (!ParsePropertyTrigger(args[i], err)) {
return false;
}
} else { // 如果是on zygote这种格式的命令
if (!event_trigger_.empty()) {
*err = "multiple event triggers are not allowed";
return false;
}
// 走到这里正常是会执行一次,比如
// on zygote-start && property:ro.crypto.state=unsupported
// 保存的会是zygote-start
event_trigger_ = args[i];
}
}
return true;
}
```
这里会遍历service的参数,由于是第一行on命令,所以可能是on zygote-start && property:ro.crypto.state=unsupported这种形式的,我们看到除了名字参数zygote-start外,后面还有属性的参数,中间用&&符号来分割。所以这里的方法首先判断参数不能为空,其次,如果除了名字外还带有属性参数,那么中间必须是&&,否则也是错误了。
经过了上面的校验,下面会就开始保存参数了。如果参数是以”property:“开头的,那么会调用ParsePropertyTrigger继续解析,否则把参数保存在event_trigger_上。
如果以”property:“开头的,那么肯定是类似property:ro.crypto.state=unsupported这样的一个形式,我们看下ParsePropertyTrigger方法是怎么处理这个字符串的:
```cpp
bool Action::ParsePropertyTrigger(const std::string& trigger, std::string* err) {
const static std::string prop_str("property:");
// 截取property:后的字符串
std::string prop_name(trigger.substr(prop_str.length()));
// 获取=号下标
size_t equal_pos = prop_name.find('=');
if (equal_pos == std::string::npos) { // 没有=号返回
*err = "property trigger found without matching '='";
return false;
}
// 获取=号后的字符串
std::string prop_value(prop_name.substr(equal_pos + 1));
// 删除等号
prop_name.erase(equal_pos);
// 保存在property_triggers_中,key是=号前面的字符串,value是=号后面的字符串
if (auto [it, inserted] = property_triggers_.emplace(prop_name, prop_value); !inserted) {
*err = "multiple property triggers found for same property";
return false;
}
return true;
}
```
这个方法首先获取property:后面的字符串,然后判断后面字符串是否有=号,没有的话说明格式不对,返回。之后分别获取等号前的字符串和等号后的字符串,保存在property_triggers_中。
好了,命令第一行的解析,service和on命令的就都分析完了,接着我们看从第二行开始的解析,同样先从service的开始看:
```cpp
bool ServiceParser::ParseLineSection(const std::vector<std::string>& args,
const std::string& filename, int line,
std::string* err) const {
return service_ ? service_->ParseLine(args, err) : false;
}
```
这里是调用ServiceParser的ParseLineSection方法。这里的service_是解析第一行命令时候创建的service对象,如果存在的话会继续调用这个对象的ParseLine方法,我们继续跟进:
```cpp
bool Service::ParseLine(const std::vector<std::string>& args, std::string* err) {
if (args.empty()) {
*err = "option needed, but not provided";
return false;
}
static const OptionParserMap parser_map;
// 返回的是OptionParserMap中map对应的一个Parsexxx
auto parser = parser_map.FindFunction(args[0], args.size() - 1, err);
if (!parser) {
return false;
}
// 调用map的parsexxx方法,返回
return (this->*parser)(args, err);
}
```
这里首先还是校验一下,传入的参数不能为空。之后这里有个类OptionParserMap,下面会调用它的FindFunction,我们看下这个类,以及看下这个方法返回的是什么。先看下OptionParserMap这个类:
```cpp
class Service::OptionParserMap : public KeywordMap<OptionParser> {
public:
OptionParserMap() {
}
private:
Map& map() const override;
};
```
可以看到这个也是个模板类,KeywordMap这个类之前我们已经看过了,他的FindFunction方法返回的类型就是这里的OptionParser,我们看下OptionParser:
```cpp
using OptionParser = bool (Service::*) (const std::vector<std::string>& args,
```
可以看到他是一个带2个参数的方法,我们再来看下KeywordMap的FindFunction方法:
```cpp
const Function FindFunction(const std::string& keyword,
size_t num_args,
std::string* err) const {
using android::base::StringPrintf;
auto function_info_it = map().find(keyword);
if (function_info_it == map().end()) {
*err = StringPrintf("invalid keyword '%s'", keyword.c_str());
return nullptr;
}
auto function_info = function_info_it->second;
auto min_args = std::get<0>(function_info);
auto max_args = std::get<1>(function_info);
if (min_args == max_args && num_args != min_args) {
*err = StringPrintf("%s requires %zu argument%s",
keyword.c_str(), min_args,
(min_args > 1 || min_args == 0) ? "s" : "");
return nullptr;
}
if (num_args < min_args || num_args > max_args) {
if (max_args == std::numeric_limits<decltype(max_args)>::max()) {
*err = StringPrintf("%s requires at least %zu argument%s",
keyword.c_str(), min_args,
min_args > 1 ? "s" : "");
} else {
*err = StringPrintf("%s requires between %zu and %zu arguments",
keyword.c_str(), min_args, max_args);
}
return nullptr;
}
return std::get<Function>(function_info);
}
```
从这个方法中可以看到,最终的返回结果是模版的类型,具体的对象是从map方法中取出的。之前我们知道取出的是一个三元组,返回的是第3个元素,所以我们现在看下OptionParserMap这个类的map方法:
```cpp
Service::OptionParserMap::Map& Service::OptionParserMap::map() const {
constexpr std::size_t kMax = std::numeric_limits<std::size_t>::max();
// clang-format off
static const Map option_parsers = {
{"capabilities",
{1, kMax, &Service::ParseCapabilities}},
{"class", {1, kMax, &Service::ParseClass}},
{"console", {0, 1, &Service::ParseConsole}},
{"critical", {0, 0, &Service::ParseCritical}},
{"disabled", {0, 0, &Service::ParseDisabled}},
{"group", {1, NR_SVC_SUPP_GIDS + 1, &Service::ParseGroup}},
{"ioprio", {2, 2, &Service::ParseIoprio}},
{"priority", {1, 1, &Service::ParsePriority}},
{"keycodes", {1, kMax, &Service::ParseKeycodes}},
{"oneshot", {0, 0, &Service::ParseOneshot}},
{"onrestart", {1, kMax, &Service::ParseOnrestart}},
{"oom_score_adjust",
{1, 1, &Service::ParseOomScoreAdjust}},
{"namespace", {1, 2, &Service::ParseNamespace}},
{"seclabel", {1, 1, &Service::ParseSeclabel}},
{"setenv", {2, 2, &Service::ParseSetenv}},
{"socket", {3, 6, &Service::ParseSocket}},
{"file", {2, 2, &Service::ParseFile}},
{"user", {1, 1, &Service::ParseUser}},
{"writepid", {1, kMax, &Service::ParseWritepid}},
};
// clang-format on
return option_parsers;
}
```
可以看到,这里同样也是一个三元组,最后一个元素也是一个方法,所以我们回到Service的ParseLine方法,这里返回了一个上面map的key对应的一个方法,然后把参数传入就去执行了。
举个例子,比如如下的命令:
```cpp
service zygote /system/bin/app_process -Xzygote /system/bin --zygote --start-system-server
class main
priority -20
user root
group root readproc
socket zygote stream 660 root system
onrestart write /sys/android_power/request_state wake
onrestart write /sys/power/state on
onrestart restart audioserver
onrestart restart cameraserver
onrestart restart media
onrestart restart netd
onrestart restart wificond
writepid /dev/cpuset/foreground/tasks
```
这里从第二行开始有很多命令,比如我们看这里的socket zygote stream 660 root system这条命令,我们从上面的map中可以看到
```cpp
{"socket", {3, 6, &Service::ParseSocket}}
```
这里对应的三元组第三个方法是Service::ParseSocket,我们跟进去看下这个方法:
```cpp
bool Service::ParseSocket(const std::vector<std::string>& args, std::string* err) {
if (args[2] != "dgram" && args[2] != "stream" && args[2] != "seqpacket") {
*err = "socket type must be 'dgram', 'stream' or 'seqpacket'";
return false;
}
return AddDescriptor<SocketInfo>(args, err); // 在do_start方法中会create和publish socket
}
```
可以看到这个方法第一个参数是一个容器,这个容器里面就是整个命令的字符串,这里首先判断下标为2的字符,即第三个必须是dgram,stream,seqpacket,这些字符串,这个表示socket的类型,这里的类型主要有三种,stream就是我们熟知的tcp连接,dgram是udp连接,seqpacket是一种传输固定长度的且必须等接受方完整接受数据后才可以读取的连接方式,这里我们了解一下就好,这个不是我们的重点。之后我们看到会调用AddDescriptor方法把参数给传过去,这个方法有个模板类是SocketInfo,他是DescriptorInfo的子类,我们稍微看下这个方法:
```cpp
bool Service::AddDescriptor(const std::vector<std::string>& args, std::string* err) {
int perm = args.size() > 3 ? std::strtoul(args[3].c_str(), 0, 8) : -1;
uid_t uid = args.size() > 4 ? decode_uid(args[4].c_str()) : 0;
gid_t gid = args.size() > 5 ? decode_uid(args[5].c_str()) : 0;
std::string context = args.size() > 6 ? args[6] : "";
auto descriptor = std::make_unique<T>(args[1], args[2], uid, gid, perm, context);
auto old =
std::find_if(descriptors_.begin(), descriptors_.end(),
[&descriptor] (const auto& other) { return descriptor.get() == other.get(); });
if (old != descriptors_.end()) {
*err = "duplicate descriptor " + args[1] + " " + args[2];
return false;
}
descriptors_.emplace_back(std::move(descriptor));
return true;
}
```
这个方法比较容易,我们看到把传过来的参数封装成模板类SocketInfo,最后存到descriptors_容器中。这里我们不讨论这个做什么用,后面分析创建socket的时候会看到descriptors_这个容器的使用,这里只是通过这个例子知道流程是怎么走的,后面启动的时候也是有这个寻找方法的流程的,这里就提前举个例子熟悉一下。
好了,回到前面,service的第二行开始的处理主要就是寻找对应的方法执行。我们接着再看下第二行开始的on命令的处理:
```cpp
bool ActionParser::ParseLineSection(const std::vector<std::string>& args,
const std::string& filename, int line,
std::string* err) const {
return action_ ? action_->AddCommand(args, filename, line, err) : false;
}
```
on命令是调用ActionParser类的ParseLineSection方法,如果第一行处理后创建的action_对象存在,则继续调用action_的AddCommand方法:
```cpp
bool Action::AddCommand(const std::vector<std::string>& args,
const std::string& filename, int line, std::string* err) {
if (!function_map_) { // function_map_包含了命令和对应方法的map,不能空
*err = "no function map available";
return false;
}
// 参数空return
if (args.empty()) {
*err = "command needed, but not provided";
return false;
}
// 寻找function_map_中对应的key的方法
auto function = function_map_->FindFunction(args[0], args.size() - 1, err);
if (!function) {
return false;
}
// 创建一个command到commands_
AddCommand(function, args, filename, line);
return true;
}
```
这个方法开头判断function_map_和args不为空,args是传入的参数自然不能为空,function_map_不知道大家还记得吗,文章开始分析init.cpp的main方法时候就提到的,指向一个模板类BuiltinFunctionMap,里面也是一堆的map,其中每个map元素的三元组都包含着一个方法。应该还记得吧,不记得的往上面看一下,这里这个也不能为空,因为下面马上要用了。
之后就调用了他的FindFunction,这个方法和前面service的逻辑一样,返回一个对应的方法,这里就不展开了。最后会调用AddCommand方法,把这个找到的方法,已经参数等一起传过去,我们再看看AddCommand方法:
```cpp
void Action::AddCommand(BuiltinFunction f,
const std::vector<std::string>& args,
const std::string& filename, int line) {
commands_.emplace_back(f, args, filename, line);
}
```
这个方法就比较简单了,把前面传过来的参数commands_这个容器中,从名字看将来会用他来执行命令,我们暂且记住这个容器,后面遇到了再说。支持on命令从第二行开始的命令处理也结束了,主要目的是添加一个Command对象到容器中。
好了,解析命令文件的第二种情况就分析完了,最重要的也就是第二种情况,下面我们在看下第一种和第三种情况。
# 解析命令完成处理
第一种情况是当遇到一个结束符的时候会调用SectionParser类的EndSection方法,这个也是分为三个子类,同样我们看下service和on的命令,先看service的:
```cpp
void ServiceParser::EndSection() {
if (service_) {
ServiceManager::GetInstance().AddService(std::move(service_));
}
}
```
可以看到这里把前面创建的service对象传入AddService方法,我们继续看这个方法:
```cpp
void ServiceManager::AddService(std::unique_ptr<Service> service) {
Service* old_service = FindServiceByName(service->name());
if (old_service) {
LOG(ERROR) << "ignored duplicate definition of service '" << service->name() << "'";
return;
}
services_.emplace_back(std::move(service));
}
```
这里首先调用FindServiceByName方法寻找是否已经保存过这个对象了,如果没有保存过则会保存在services_中,services_是一个容器。到这里我们也就知道了,service的EndSection方法就是把一个service对象保存在services_容器中。
我们在看下on命令的EndSection方法:
```cpp
void ActionParser::EndSection() {
if (action_ && action_->NumCommands() > 0) { // 有action的情况下
ActionManager::GetInstance().AddAction(std::move(action_));
}
}
```
on命令是调用的ActionParser的EndSection方法,如果之前创建的action_存在的话,就继续调用AddAction方法:
```cpp
void ActionManager::AddAction(std::unique_ptr<Action> action) {
auto old_action_it =
std::find_if(actions_.begin(), actions_.end(),
[&action] (std::unique_ptr<Action>& a) {
return action->TriggersEqual(*a);
});
if (old_action_it != actions_.end()) {
// 找到相同的action,往对应action添加进新的命令
(*old_action_it)->CombineAction(*action);
} else {
// 没有找到就直接把action加入容器
actions_.emplace_back(std::move(action));
}
}
```
这个方法也比较容易。首先还是寻找是否容器中已经有了这个action,如果已经有了,那么说明现在这个action又有新的要执行的命令了,所以调用CombineAction方法把新的方法添加到这个action的命令容器中。如果没有找到,则把action添加到action容器中。到这里可以看到action的EndSection方法主要就是把新的action添加到容器中以及更新老的action的执行命令。
# 处理非结束和换行时候的字符串
到这里,命令的EndSection部分也分析完了,剩下还有第三种情况,读取一段字符串后返回的处理。由于离开上面文章比较远了,这里在贴一下:
```cpp
case T_TEXT: // 返回的是正常的一行字符串,放入string容器中
args.emplace_back(state.text);
break;
```
第三种情况比较容易,就是把返回的字符串添加到args中,之后进入第二种情况后,就会使用这个args。
到这里所有解析命令文件就基本完成了,可以看到这里处理的结果主要就是把这些命令字符串格式化的保存在某个地方,后面执行的时候就可以方便的使用了。好了,下面我们就开始看怎么执行了。
# init.rc中和启动zygote有关的命令
我们回到init.cpp的main方法,看下执行前面解析的命令是怎么处理的。这里执行的代码其实就一句话,调用ActionManager的ExecuteOneCommand方法:
```cpp
ActionManager& am = ActionManager::GetInstance();
.............
am.ExecuteOneCommand();
..........
# 和zygote有关的init.rc文件命令
```
虽然只有一句话,那肯定事情都是在ExecuteOneCommand方法里面做到,在说这个方法之前,我们再看一眼init.rc这文件,我们后面要启动zygote进程和这里面的几个命令有关,所以先看一下,后面分析也比较好理解。
```cpp
on late-init
.......
trigger zygote-start
.......
```
首先看这个on命令。这里里面有个trigger命令,根据前面我们分析的,trigger解析的时候会触发到一个方法,然后会把这后面的参数传到那个方法中,我们找下那个方法。
具体方法在BuiltinFunctionMap这个类中,我们找到其中的三元组:
```cpp
{"trigger", {1, 1, do_trigger}},
```
可以看到这里调用的是do_trigger方法,我们跟进去看:
```cpp
static int do_trigger(const std::vector<std::string>& args) {
ActionManager::GetInstance().QueueEventTrigger(args[1]);
return 0;
}
void ActionManager::QueueEventTrigger(const std::string& trigger) {
trigger_queue_.push(std::make_unique<EventTrigger>(trigger));
}
```
跟到最后,可以看到这里最终是把参数保存在trigger_queue_这个队列中,我们先记住这个队列的名字,他里面保存了一个字符串,名字是zygote-start。
好,我们继续看init.rc文件中另一个命令:
```cpp
on zygote-start && property:ro.crypto.state=unsupported
# A/B update verifier that marks a successful boot.
exec_start update_verifier_nonencrypted
start netd
start zygote
start zygote_secondary
```
这也是一个on命令,名字是zygote-start,根据我们之前解析on命令的分析,会把on命令的名字存放在action对象的event_trigger_变量中,不记得的同学可以往上再翻一下。之后第二行开始就会被创建一个command命令,这里我们要注意的是start zygote这条命令,我们看看start这条命令对应执行的方法是什么,老规矩去找对应的三元组:
```cpp
{"start", {1, 1, do_start}},
```
这里调用的是do_start方法,我们看一下:
```cpp
static int do_start(const std::vector<std::string>& args) {
Service* svc = ServiceManager::GetInstance().FindServiceByName(args[1]);
if (!svc) {
LOG(ERROR) << "do_start: Service " << args[1] << " not found";
return -1;
}
if (!svc->Start())
return -1;
return 0;
}
```
这里被传进来的参数是zygote,然后会调用FindServiceByName方法去寻找有没有这个名字的service,我们在本文就已经介绍过一个service了,如下:
```cpp
service zygote /system/bin/app_process -Xzygote /system/bin --zygote --start-system-server
class main
priority -20
user root
group root readproc
socket zygote stream 660 root system
onrestart write /sys/android_power/request_state wake
onrestart write /sys/power/state on
onrestart restart audioserver
onrestart restart cameraserver
onrestart restart media
onrestart restart netd
onrestart restart wificond
writepid /dev/cpuset/foreground/tasks
```
看吧,这个service名字就是zygote,所以是可以找得到的,所以后面就会执行service的Start方法,这个方法这里就暂时不说了,放在后面再说。以上这些只不过是在介绍执行解析文件前大致熟悉一下,这样对执行的流程也能比较好的理解。好了下面回到init.cpp的main方法,我们开始说执行命令的流程。
# 执行init.rc中解析出来的命令
前面说到了执行命令的方法是ActionManager的ExecuteOneCommand,我们去看看:
```cpp
void ActionManager::ExecuteOneCommand() {
// Loop through the trigger queue until we have an action to execute
// current_executing_actions_当前正在执行的action是空
// trigger_queue_等待执行的事件不空
while (current_executing_actions_.empty() && !trigger_queue_.empty()) {
// 遍历前面add的action
for (const auto& action : actions_) {
// 检查trigger触发的on命令和actions_集合是不是一个
if (trigger_queue_.front()->CheckTriggers(*action)) {
// 匹配的话把action加入current_executing_actions_队列
current_executing_actions_.emplace(action.get());
}
}
// 弹出一个等待执行的队头元素
trigger_queue_.pop();
}
// 当前正在执行的队列为空,return
if (current_executing_actions_.empty()) {
return;
}
// 取出当前正在执行的队头元素
auto action = current_executing_actions_.front();
if (current_command_ == 0) {
std::string trigger_name = action->BuildTriggersString();
LOG(INFO) << "processing action (" << trigger_name << ")";
}
// 执行这个action
action->ExecuteOneCommand(current_command_);
// If this was the last command in the current action, then remove
// the action from the executing list.
// If this action was oneshot, then also remove it from actions_.
++current_command_;
if (current_command_ == action->NumCommands()) {
current_executing_actions_.pop();
current_command_ = 0;
if (action->oneshot()) {
auto eraser = [&action] (std::unique_ptr<Action>& a) {
return a.get() == action;
};
actions_.erase(std::remove_if(actions_.begin(), actions_.end(), eraser));
}
}
}
```
方法不算长,我们先整体介绍下整个方法的逻辑。首先current_executing_actions_是一个保存当前正在执行的Action,开始时肯定是空。而trigger_queue_队列我们上面讲解init.rc的时候有说到保存了一个trigger命令的参数,比如上面我们说到的zygote-start这个字符串,trigger_queue_队列如果有数据的话,那么下面就开始遍历actions_容器,寻找是否有需要执行的action了。
这里寻找匹配的条件是调用trigger_queue_队列的元素的CheckTriggers方法,这个方法我们待会看,先继续这里看下去。如果找到一个合适的action,会把他加入current_executing_actions_队列,只要找到一个action这里就不继续寻找了,下面会调用这个action的ExecuteOneCommand方法,这个方法我们也待会看。
由于在init.cpp中执行ActionManager是在一个ExecuteOneCommand循环中的,所以会不断地取出action执行,直到没有为止。这个方法的逻辑还是比较清晰的,我们接下来就看下上面提到的两个方法,先看第一个方法CheckTriggers,他是从trigger_queue_队列中取出的元素,即一个EventTrigger对象的方法:
```cpp
bool CheckTriggers(const Action& action) const override {
return action.CheckEventTrigger(trigger_);
}
```
这个方法调用传入的参数,一个Action对象的CheckEventTrigger方法,把自己的trigger_作为参数传入:
```cpp
bool Action::CheckEventTrigger(const std::string& trigger) const {
return !event_trigger_.empty() &&
trigger == event_trigger_ &&
CheckPropertyTriggers();
}
```
这里event_trigger_是on命令的名字,trigger是前面传过来的trigger的参数,由前面的init.rc文件我们分析的例子,这里存在一个名为zygote-start的action,同时也存在zygote-start的trigger,而这里CheckPropertyTriggers也是返回true的,我们看下这个方法:
```cpp
bool CheckPropertyTriggers(const std::string& name = "",
const std::string& value = "") const;
bool Action::CheckPropertyTriggers(const std::string& name,
const std::string& value) const {
if (property_triggers_.empty()) {
return true;
}
bool found = name.empty();
for (const auto& [trigger_name, trigger_value] : property_triggers_) {
if (trigger_name == name) {
if (trigger_value != "*" && trigger_value != value) {
return false;
} else {
found = true;
}
} else {
std::string prop_val = android::base::GetProperty(trigger_name, "");
if (prop_val.empty() || (trigger_value != "*" && trigger_value != prop_val)) {
return false;
}
}
}
return found;
}
```
这个方法是带2各参数的,而前面调用的时候是没带参数,默认参数是空,所以这里返回是true。至此CheckTriggers方法就分析完了,这里返回true后,被执行的action就会加入trigger_queue_队列,接着就会从这个队列中取出action,调用它的ExecuteOneCommand方法来执行,我们接着看action的执行方法。
# action执行
```cpp
void Action::ExecuteOneCommand(std::size_t command) const {
// We need a copy here since some Command execution may result in
// changing commands_ vector by importing .rc files through parser
Command cmd = commands_[command];
ExecuteCommand(cmd);
}
```
之前调用处的每次循环都会执行这个action中的一个command,直到全部执行完毕,这个方法从action的commands_容器中取出一条命令,接着调用ExecuteCommand来执行:
```cpp
void Action::ExecuteCommand(const Command& command) const {
Timer t;
int result = command.InvokeFunc();
double duration_ms = t.duration_s() * 1000;
// Any action longer than 50ms will be warned to user as slow operation
if (duration_ms > 50.0 ||
android::base::GetMinimumLogSeverity() <= android::base::DEBUG) {
std::string trigger_name = BuildTriggersString();
std::string cmd_str = command.BuildCommandString();
std::string source = command.BuildSourceString();
LOG(INFO) << "Command '" << cmd_str << "' action=" << trigger_name << source
<< " returned " << result << " took " << duration_ms << "ms.";
}
}
```
这个方法调用command的InvokeFunc方法:
```cpp
int Command::InvokeFunc() const {
std::vector<std::string> expanded_args;
expanded_args.resize(args_.size());
expanded_args[0] = args_[0];
for (std::size_t i = 1; i < args_.size(); ++i) {
if (!expand_props(args_[i], &expanded_args[i])) {
LOG(ERROR) << args_[0] << ": cannot expand '" << args_[i] << "'";
return -EINVAL;
}
}
// 执行命令,expanded_args是参数,比如zygote,对应到init32或者64等import的rc文件中的命令
return func_(expanded_args);
}
```
这个expanded_args是将要执行方法的参数,func_就是之前分析的三元组中的方法,这里就调用这个command在三元组中的方法了。比如根据前面我们分析的start zygote这条命令,就会调用到service的do_start方法,最后会走到Start方法。这个方法中就会开启zygote进程,我们看下开启前做的一些事情:
```cpp
bool Service::Start() {
............
pid_t pid = -1;
if (namespace_flags_) {
pid = clone(nullptr, nullptr, namespace_flags_ | SIGCHLD, nullptr);
} else {
pid = fork();
}
if (pid == 0) {
// 进这是新进程,即zygote进程
umask(077);
if (namespace_flags_ & CLONE_NEWPID) {
// This will fork again to run an init process inside the PID
// namespace.
SetUpPidNamespace(name_);
}
for (const auto& ei : envvars_) {
add_environment(ei.name.c_str(), ei.value.c_str());
}
// 创建socket
std::for_each(descriptors_.begin(), descriptors_.end(),
std::bind(&DescriptorInfo::CreateAndPublish, std::placeholders::_1, scon));
...............
std::vector<char*> strs;
// 参数保存到strs
ExpandArgs(args_, &strs);
// 执行service,
if (execve(strs[0], (char**) &strs[0], (char**) ENV) < 0) {
PLOG(ERROR) << "cannot execve('" << strs[0] << "')";
}
_exit(127);
}
if (pid < 0) {
PLOG(ERROR) << "failed to fork for '" << name_ << "'";
pid_ = 0;
return false;
}
...........
return true;
}
```
这个方法就会开启一个新进程了。我们知道后续的进程都是由zygote进程fork出来的,现在我们分析init源码也可以知道了zygote进程是在这里有init进程fork出来的。熟悉linux的同学一定知道,fork一个进程后,会返回2次,一次是在父进程返回,一次是在子进程。父进程返回的值是子进程的pid,子进程返回的值是0,如果返回小于0的值,就说明错误了。我们这里主要看pid为0的值,也就是说下面的代码已经进入zygote进程了。
# socket的创建和注册
这里首先设置些权限码,接着会创建socket,我们知道android之前的通信后面都是通过binder来进行的,而目前离binder起来还早呢,binder需要再system service起来后才能正常运行,而system service是在systemserver中起来的,systemserver又是由zygote给fork出来的,现在zygote才刚起来所以binder不可能在这里使用,所以只有借助linux的socket通信方法在进程间通信,所以这里会先创建socket,后面就可以使用socket了。这里会遍历descriptors_这个容器,这个容器还记得吗,上面说过从init.rc文件的service命令解析的socket命令会被创建一个DescriptorInfo对象(实际是SocketInfo对象,SocketInfo是DescriptorInfo的子类),然后加入到这个容器中。这里每一个DescriptorInfo对象就要创建一个socket,我们之前解析service zygote的时候是有一个这个对象,所以会调用CreateAndPublish方法来创建socket,我们看下这个方法:
```cpp
void DescriptorInfo::CreateAndPublish(const std::string& globalContext) const {
// Create
const std::string& contextStr = context_.empty() ? globalContext : context_;
// 创建socket,返回fd小于0,return
int fd = Create(contextStr);
if (fd < 0) return;
// Publish
std::string publishedName = key() + name_;
std::for_each(publishedName.begin(), publishedName.end(),
[] (char& c) { c = isalnum(c) ? c : '_'; });
std::string val = android::base::StringPrintf("%d", fd);
// 添加这个socket到环境变量,key为ANDROID_SOCKET_ENV_PREFIX_zygote,val为fd
add_environment(publishedName.c_str(), val.c_str());
// make sure we don't close on exec
// 设置这个文件被执行后,不会关闭
fcntl(fd, F_SETFD, 0);
}
```
这个方法我们看到开始会调用Create创建一个socket,返回的是这个socket的文件描述符fd。之后需要添加这个socket到环境变量中,这样其他进程就可以使用这个socket进行进程间的通信了。添加到环境变量中需要有key和value,value就是前面创建的socket的文件描述符fd。key是一个字符串,由key()这个方法和name_变量组合而成,key()方法如下:
```cpp
const std::string SocketInfo::key() const {
return ANDROID_SOCKET_ENV_PREFIX;
}
```
返回的是ANDROID_SOCKET_ENV_PREFIX这个常量,这个常量的定义是一个字符串:
```cpp
#define ANDROID_SOCKET_ENV_PREFIX "ANDROID_SOCKET_"
```
而name_的值是在DescriptorInfo对象初始化时候被赋值的:
```cpp
DescriptorInfo::DescriptorInfo(const std::string& name, const std::string& type, uid_t uid,
gid_t gid, int perm, const std::string& context)
: name_(name), type_(type), uid_(uid), gid_(gid), perm_(perm), context_(context) {
}
```
这个DescriptorInfo初始化的参数就是在解析socket命令时候的参数,他的第一个参数就是zygot,可以在看下这个命令:
```cpp
socket zygote stream 660 root system
```
好了,这样的话这个socket注册到环境变量中的可以完整的名字就是ANDROID_SOCKET_zygote,我们后面就会通过这个名字来取出socket使用,这个到后面遇到了再说。这样socket就完成了,我们在回过头上去看下创建socket的方法Create:
```cpp
int SocketInfo::Create(const std::string& context) const {
int flags = ((type() == "stream" ? SOCK_STREAM :
(type() == "dgram" ? SOCK_DGRAM :
SOCK_SEQPACKET)));
return create_socket(name().c_str(), flags, perm(), uid(), gid(), context.c_str());
}
```
这里获取socket的类型后,继续调用create_socket方法来创建:
```cpp
int create_socket(const char *name, int type, mode_t perm, uid_t uid,
gid_t gid, const char *socketcon)
{
................
// 建立一个域套接字,即PF_UNIX,实现进程间的数据复制
android::base::unique_fd fd(socket(PF_UNIX, type, 0));
if (fd < 0) {
PLOG(ERROR) << "Failed to open socket '" << name << "'";
return -1;
}
if (socketcon) setsockcreatecon(NULL);
struct sockaddr_un addr;
// 地址初始化为0
memset(&addr, 0 , sizeof(addr));
// 表示是域套接字,进程间通信
addr.sun_family = AF_UNIX;
// 设备文件路径/dev/socket/zygote
snprintf(addr.sun_path, sizeof(addr.sun_path), ANDROID_SOCKET_DIR"/%s",
name);
// 删除这个路径下的文件,可能是一个老文件
if ((unlink(addr.sun_path) != 0) && (errno != ENOENT)) {
PLOG(ERROR) << "Failed to unlink old socket '" << name << "'";
return -1;
}
..............
//将这个地址和文件绑定,即这个地址的sun_path路径下有个文件,是上面fd代表的socket
int ret = bind(fd, (struct sockaddr *) &addr, sizeof (addr));
int savederrno = errno;
.........
// 设置用户id,权限等
if (lchown(addr.sun_path, uid, gid)) {
PLOG(ERROR) << "Failed to lchown socket '" << addr.sun_path << "'";
goto out_unlink;
}
............
return fd.release();
out_unlink:
unlink(addr.sun_path);
return -1;
}
```
创建socket的方法是socket,这个会调用linux系统的创建方法我们就不跟进去看了,创建成功后就会返回文件描述符fd。这里的参数PF_UNIX以及下面的参数AF_UNIX简单说一下,我们平时熟知的网络通信也是用的socket,而这里我们创建socket并不是用于网络通信的,而是进行进程间的通信的,其实也是可以用socket的,只要创建的时候用PF_UNIX这个参数就可以了,这个参数表示的是域通信,他不需要通过网络的那些协议,也不需要经过网卡,只是把数据复制到内核进行中转,然后再赋值到目标进程,大家可以对比着之前我们讲过的binder来理解,之前讲binder的时候进程间通信只需要一次赋值,而这里socket需要两次复制,所以它的效率肯定是没有binder高的,这就是为什么之后binder起来了之后就会改用binder的原因,这里由于还在初始化阶段,binder还未建立,所以目前只能用socket来进行通信。好了,我们回到上面创建的方法。
socket创建完之后,需要有一个通信的地址,这个可以这样理解,一般我们知道网络通信都需要有ip地址,端口之类的,而这里由于是域通信,所以没有什么ip地址和端口的概念,但是根据前面我们描述的socket,他如果处理在进程间通信的话,会把内核的一块区域作为缓冲区,进程间进行通信的时候会通过这块缓冲区作为中介进行数据的赋值,所以这里的通信理解就可以理解为这个中介的缓冲区。
这里设置一个文件路径作为缓冲区的地址,会把ANDROID_SOCKET_DIR+name这个路径作为地址,这个路径最终实际的地址是/dev/socket/zygote,所以我们可以手机的这个目录下看到zygtoe这个文件。
最后调用bind方法把fd文件描述符和这个通信地址绑定起来,这样其他进程通过前面注册在环境变量中的socket就可以进行通信了。好了,socket的创建就说到这里,大家对socket有了一个大致理解后,后面分析代码中遇到socket就不会太陌生了。
# 执行zygote的main方法
我们回到service的start方法,接下来会调用ExpandArgs方法把启动zygote进程的参数封装下:
```cpp
static void ExpandArgs(const std::vector<std::string>& args, std::vector<char*>* strs) {
std::vector<std::string> expanded_args;
expanded_args.resize(args.size());
// 第一个service参数,即执行文件路径,比如zygote就是/system/bin/app_process
strs->push_back(const_cast<char*>(args[0].c_str()));
for (std::size_t i = 1; i < args.size(); ++i) {
if (!expand_props(args[i], &expanded_args[i])) {
LOG(FATAL) << args[0] << ": cannot expand '" << args[i] << "'";
}
strs->push_back(const_cast<char*>(expanded_args[i].c_str()));
}
strs->push_back(nullptr);
}
```
这个方法也比较简单,把前面传过来的参数存到strs这个容器中。注意这里第一个参数对应的是/system/bin/app_process,这个我们在本文开头就已经有过讨论了,最终他对应的执行文件是frameworks/base/cmds/app_process/app_main.cpp这个文件。后面会执行execve(strs[0], (char**) &strs[0], (char**) ENV)方法,执行后会从这个文件的main方法开始分析,也就是正式开始了zygote进程的部分了。好了,这篇文章已经说了不少了,我们把init进程的流程基本都说了,下一篇文章就开始zygote进程的部分,这里我们先把init进程的时序图画一下:
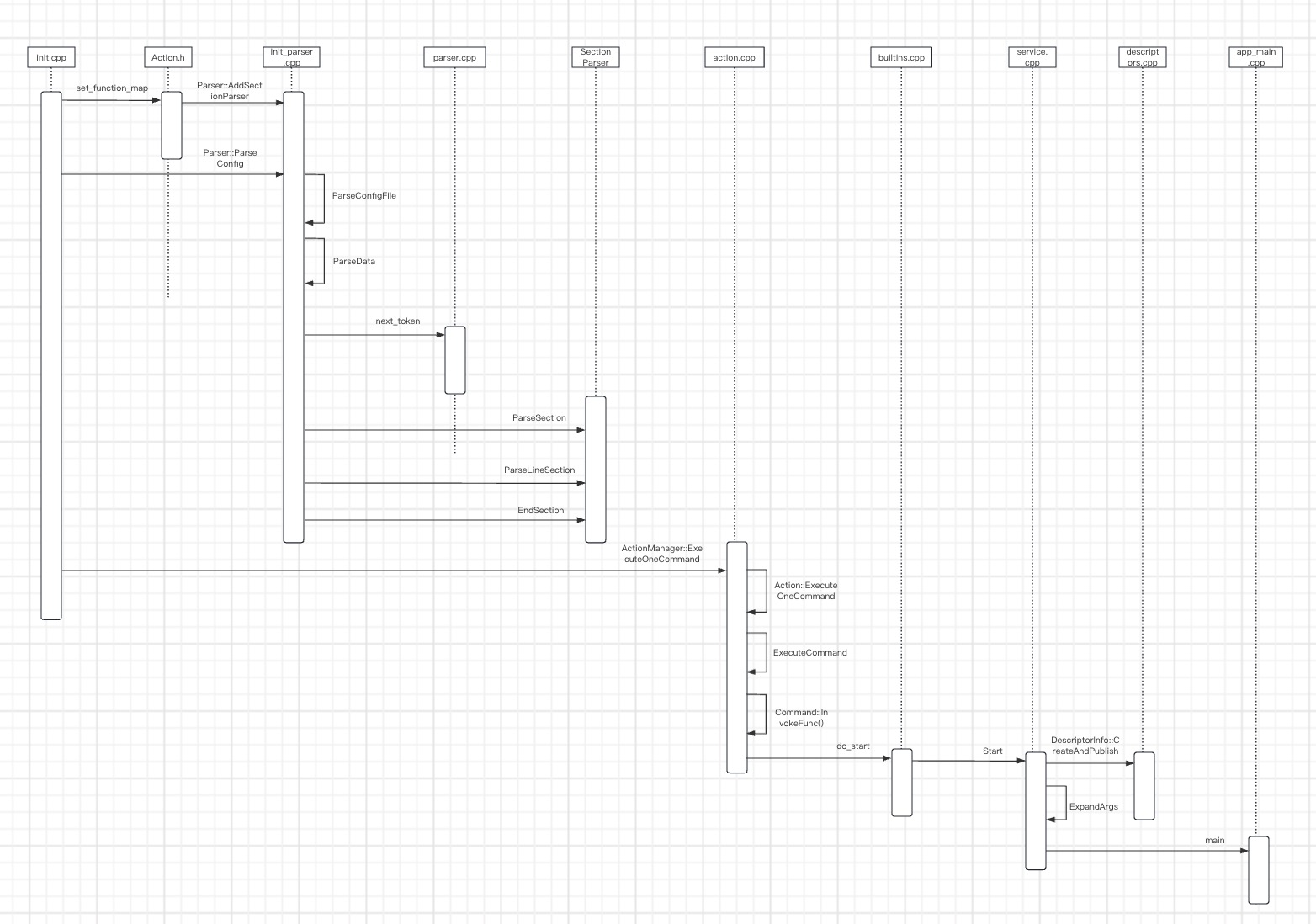

android启动之init进程